Apache Kylin3.0.1对接FusionInsight HD¶
适用场景¶
Apache Kylin 3.0.1 ↔ FusionInsight HD 6.5 (Hive/HBase/Kafka/Spark)
说明¶
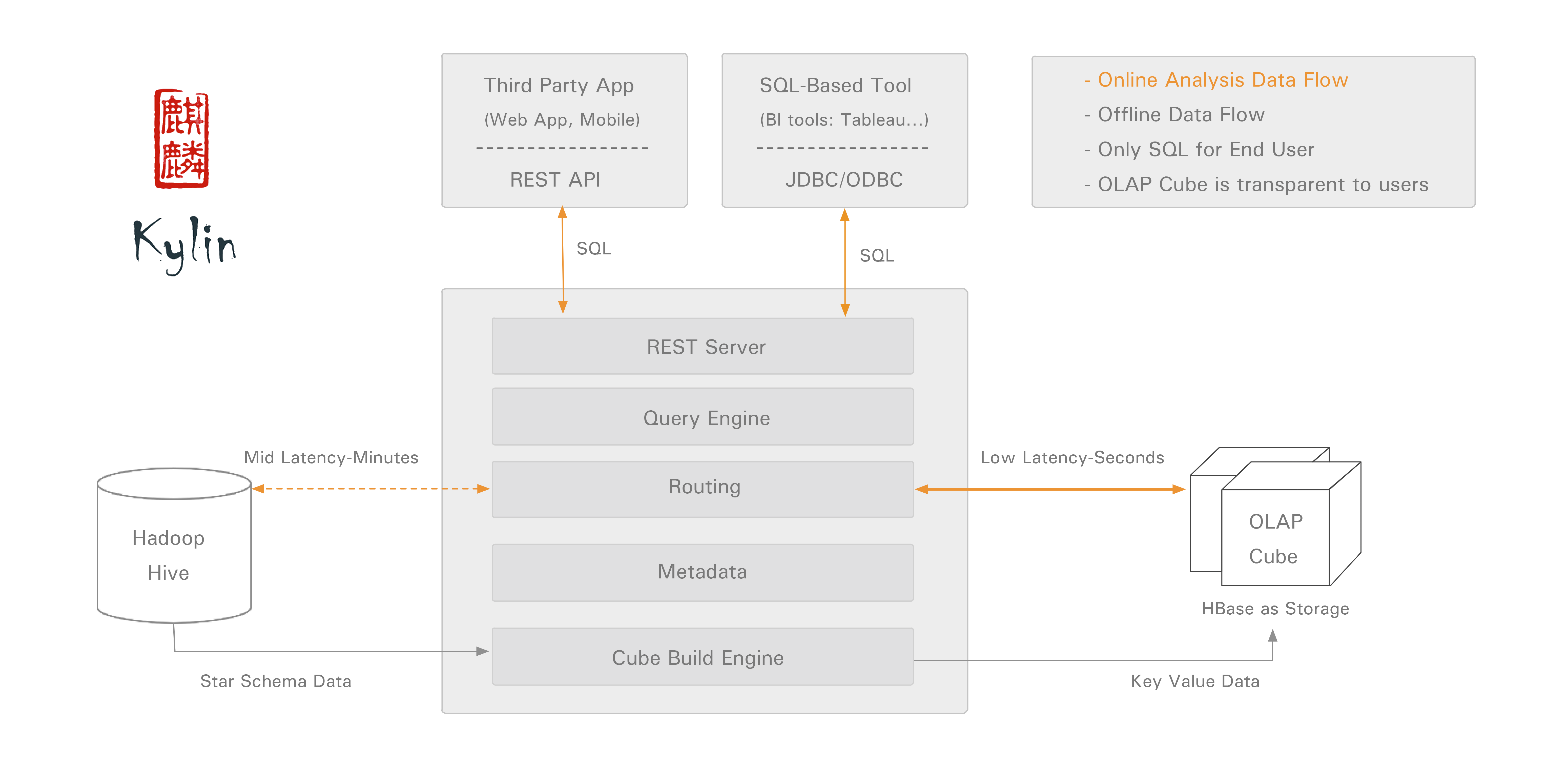
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
Apache Kylin主要与FusionInsight的Hive和HBase进行对接
如果需要读取hive分区表需要修改源码,本文不提供该方法
环境准备¶
- 修改/etc/hosts
添加本机主机名解析
172.16.52.86 kylin
- 配置NTP服务(若kylin主机与集群时间在5min之内此步骤可选)
使用vi /etc/ntp.conf增加NTP服务的配置,时间与FusionInsight集群同步
server 172.18.0.18 nomodify notrap nopeer noquery
启动NTP服务
service ntpd start
chkconfig ntpd on
- 参考FusionInsight产品文档在Kylin节点安装FusionInsight客户端
在FusionInsight Manager服务管理页面下载客户端,上传到kylin节点安装FusionInsight客户端到/opt/hadoopclient目录
./install.sh /opt/135_651armhdclient/hadoopclient
- 安装JDK1.8(可选)
rpm -Uvh jdk-8u112-linux-x64.rpm
下载Kylin¶
Fusioninsight配套的HBase是1.3.1,Apache Kylin可直接下载apache-kylin-3.0.1-hbase1x-bin.tar.gz主版本二进制包,无需编译Apache kylin
下载解压Kylin¶
-
下载Kylin-3.0.1基于HBase1.x版本的二进制包: https://www.apache.org/dyn/closer.cgi/kylin/apache-kylin-3.0.1/apache-kylin-3.0.1-bin-hbase1x.tar.gz
-
上传apache-kylin-3.0.1-hbase1x-bin.tar.gz到Apache kylin节点的
/opt目录 -
解压上一步骤的安装包
cd /opt/kylin tar -xvf apache-kylin-3.0.1-bin-hbase1x.tar.gz
配置Kylin¶
配置环境变量¶
-
配置环境变量:
vi /etc/profile,增加以下配置export KYLIN_HOME=/opt/kylin/apache-kylin-3.0.1-bin-hbase1x -
导入环境变量
source /etc/profile -
Kylin启动还需要配置HIVE_CONF、HCAT_HOME,使用
vi /opt/135_651armhdclient/hadoopclient/Hive/component_env,在文件最后增加export HIVE_CONF=/opt/135_651armhdclient/hadoopclient/Hive/config export HCAT_HOME=/opt/135_651armhdclient/hadoopclient/Hive/HCatalog -
导入环境变量
source /opt/135_651armhdclient/hadoopclient/bigdata_env -
进行kerberos认证
kinit developuser -
Kylin检查环境设置:
cd /opt/kylin/apache-kylin-3.0.1-bin-hbase1x/bin ./check-env.sh
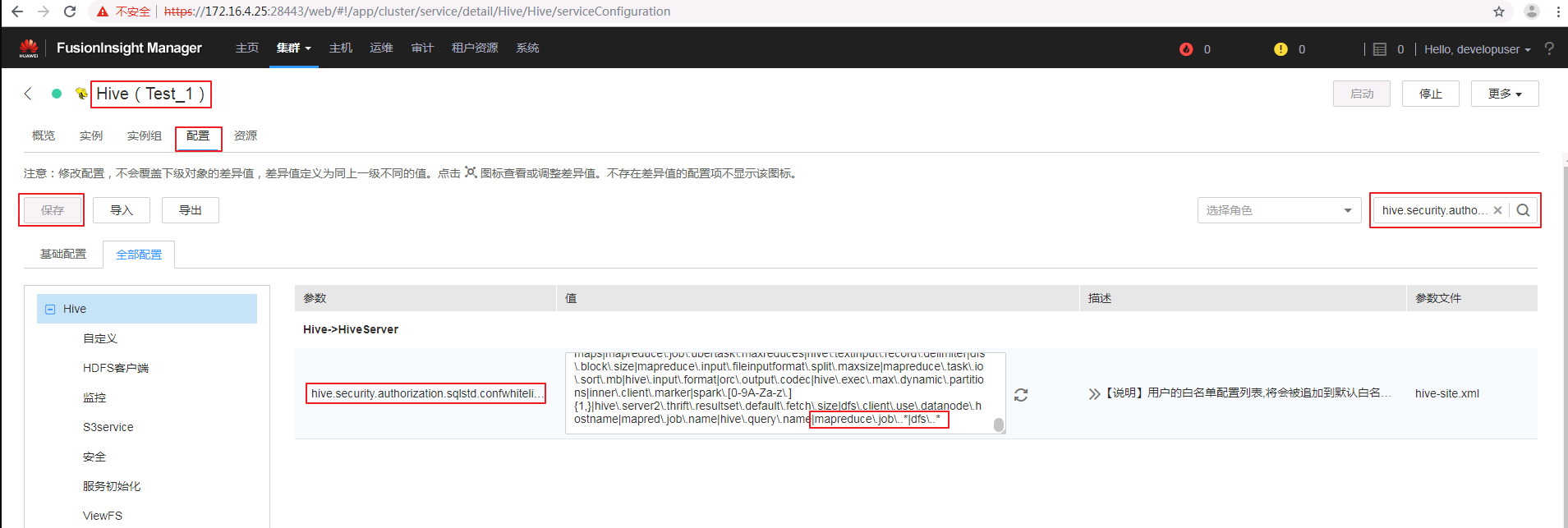
修改FusionInsight的Hive配置项¶
- 在hive.security.authorization.sqlstd.confwhitelist.append参数最后追加一下参数配置,保存配置,重启影响的服务
|mapreduce\.job\..*|dfs\..*|mapred\..*
修改Kylin配置¶
- 获取Hive的JDBC字符串
执行Beeline查看Hive的JDBC字符串
source bigdata_env
kinit developuser
beeline

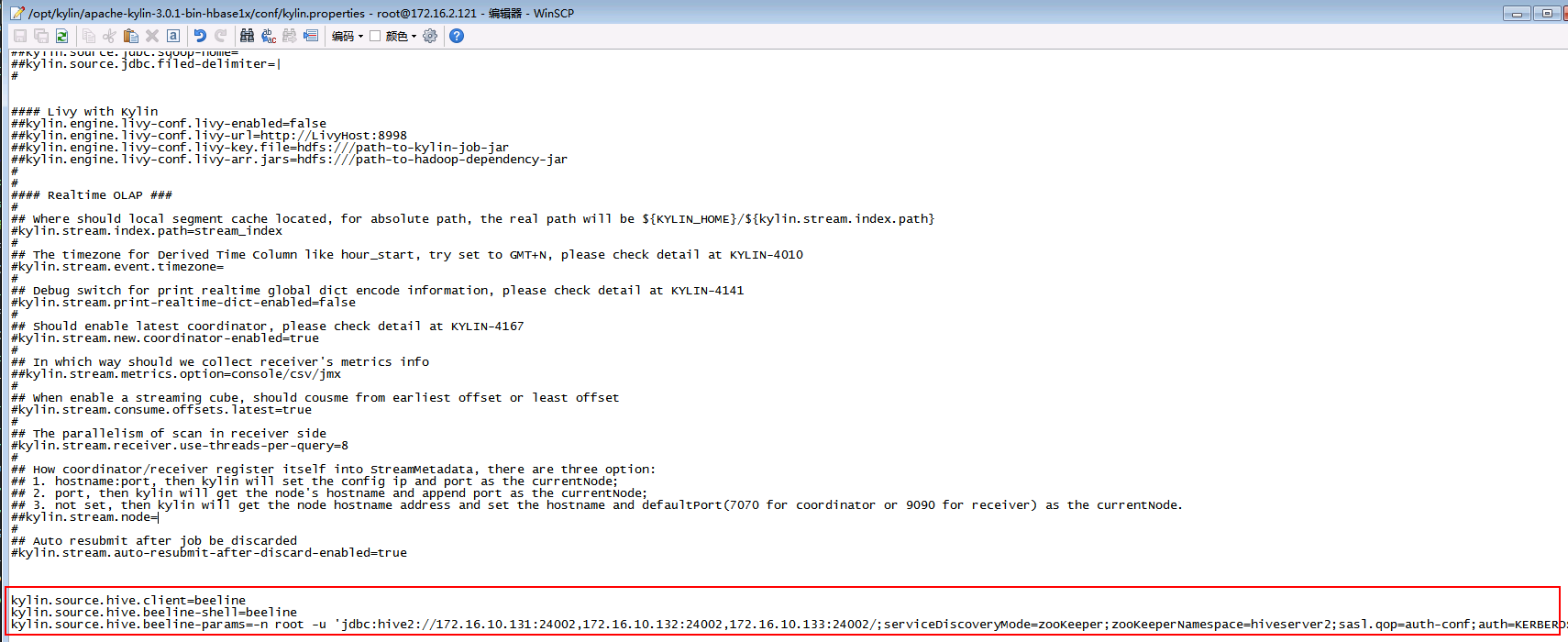
- 修改kylin.properties:
vi /opt/kylin/apache-kylin-3.0.1-bin-hbase1x/conf/kylin.properties
配置Hive client使用beeline:
kylin.source.hive.client=beeline
kylin.source.hive.beeline-shell=beeline
kylin.source.hive.beeline-params=-n root -u 'jdbc:hive2://172.16.10.131:24002,172.16.10.132:24002,172.16.10.133:24002/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2;sasl.qop=auth-conf;auth=KERBEROS;principal=hive/hadoop.hadoop.com@HADOOP.COM'
注意:kylin.source.hive.beeline-params参数里面原有的
--hiveconf hive.security.authorization.sqlstd.confwhitelist.append='mapreduce.job.*|dfs.*'要去掉
- 修改Hive/HBase配置
将/opt/135_651armhdclient/hadoopclient/Hive/config/hivemetastore-site.xml中的配置合并到hive-site.xml
将/opt/135_651armhdclient/hadoopclient/HBase/hbase/conf/hbase-site.xml中的配置合并到/opt/kylin/apache-kylin-3.0.1-bin-hbase1x/conf/kylin_job_conf.xml
- Hive lib路径
kylin的/opt/kylin/apache-kylin-3.0.1-bin-hbase1x/bin/find-hive-dependency.sh默认Hive lib路径为大数据集群中Hive的安装路径,需要修改为客户端路径

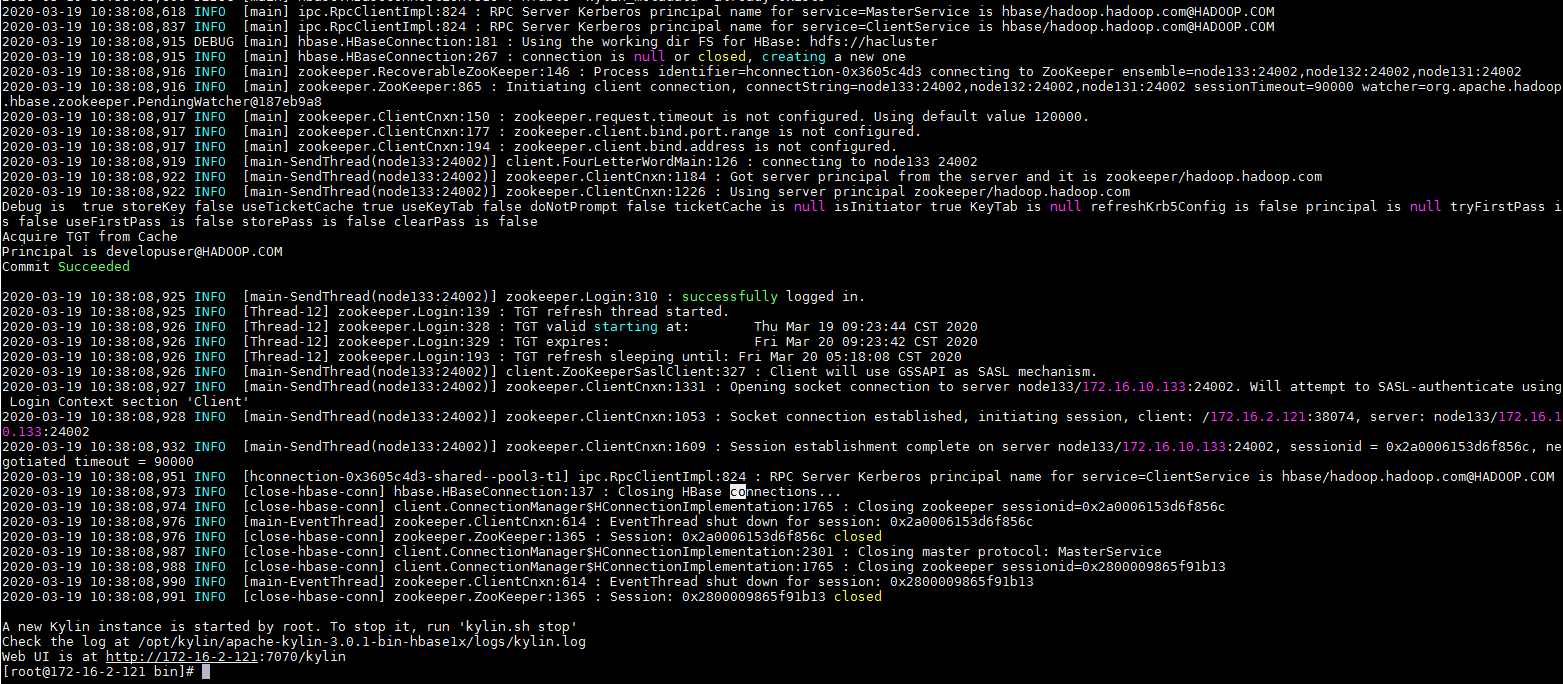
启动Kylin¶
- 使用
./kylin.sh start启动Kylin
输入默认用户名密码:ADMIN/KYLIN登陆
Demo测试¶
导入Demo数据¶
- 执行以下命令导入sample数据
cd /opt/kylin/apache-kylin-3.0.1-bin-hbase1x/bin ./sample.sh

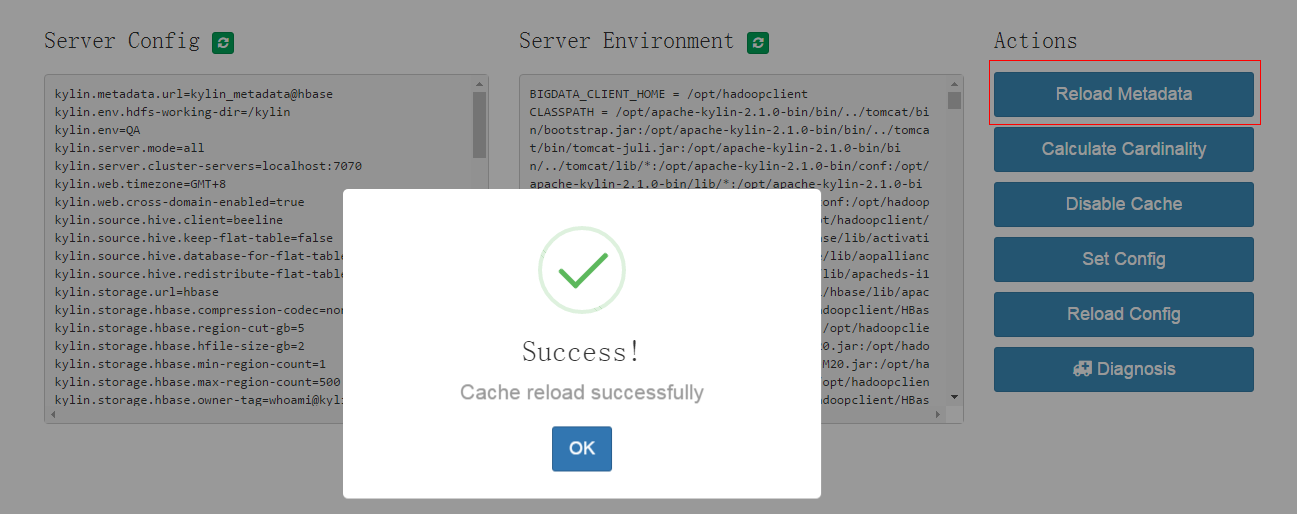
选择菜单 System -> Actions -> Reload Metadata
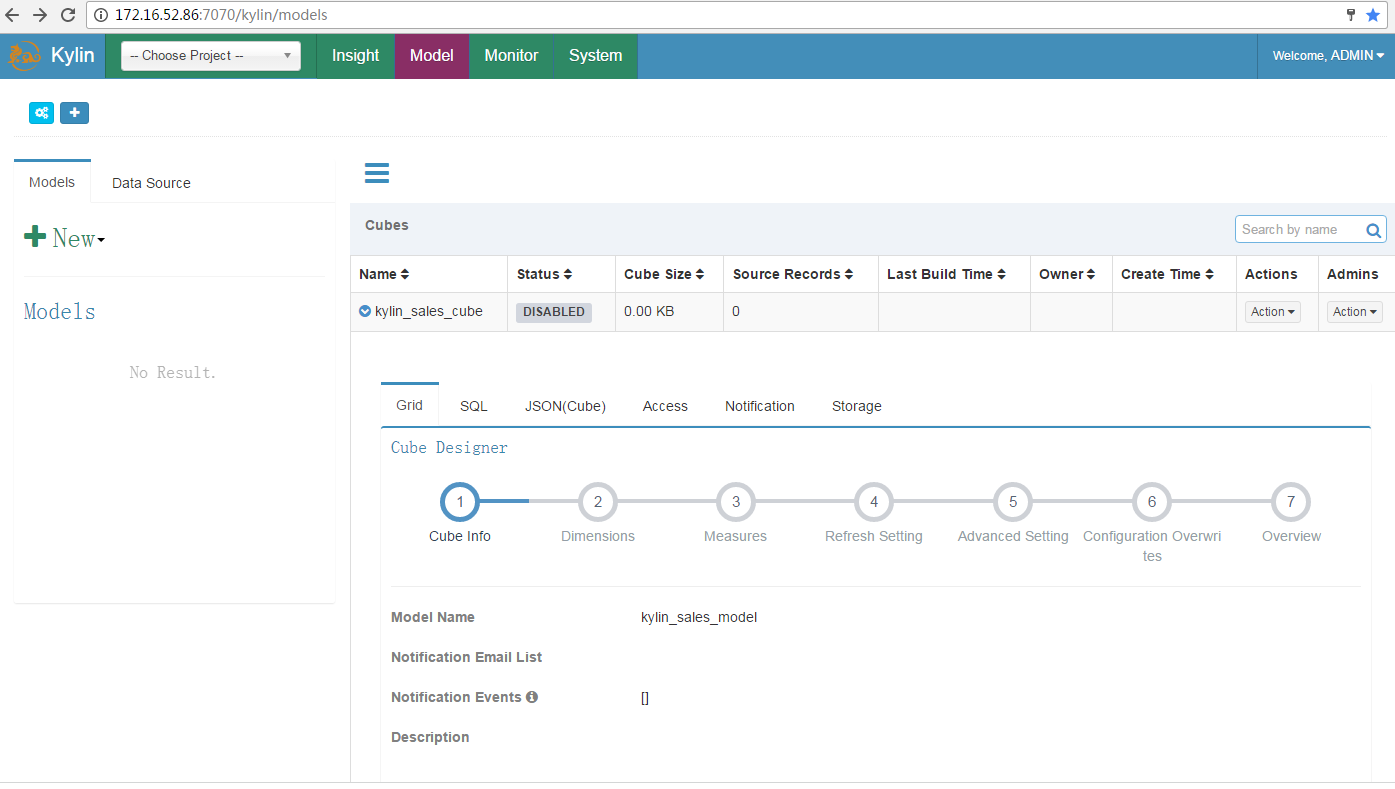
选择菜单 System -> Model
构建Cube¶
- 构建默认的kylin_sales_cube
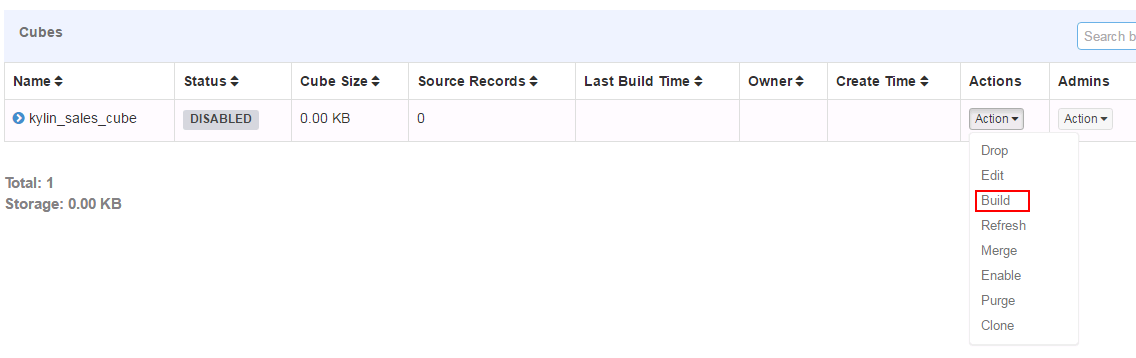
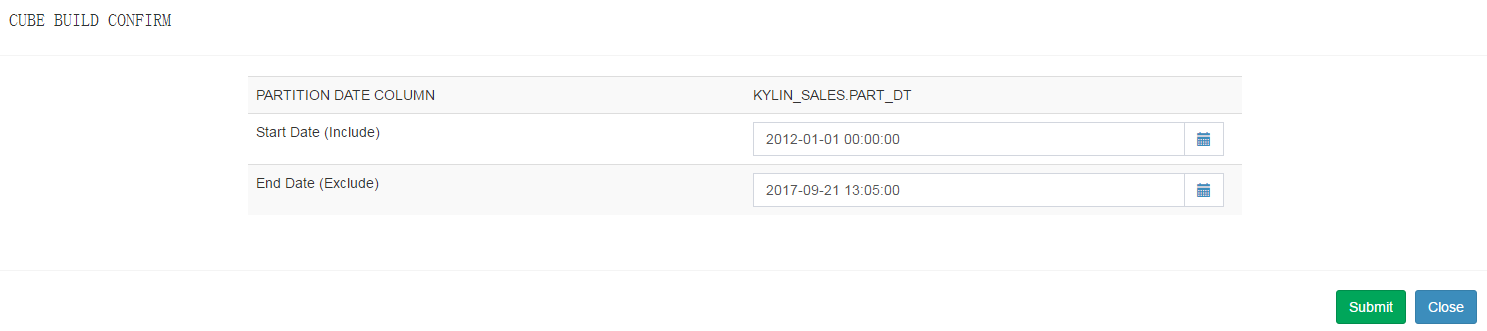
- 选择End Data(Exclude)时间:
- 点击Monitor可以查看build状态:
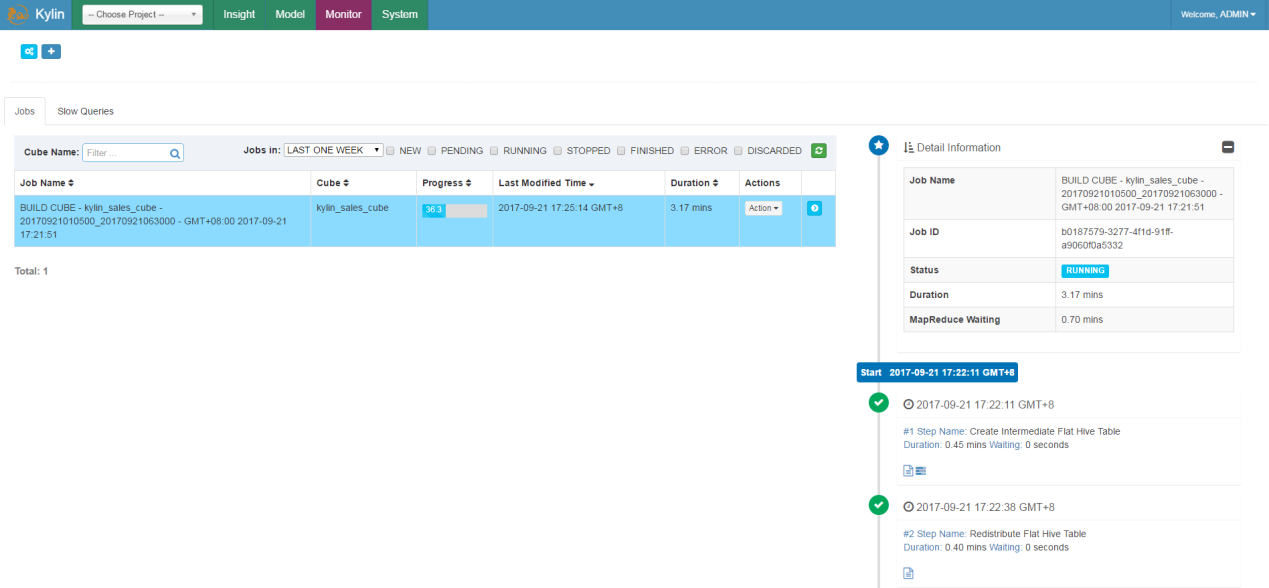
- Build完成:
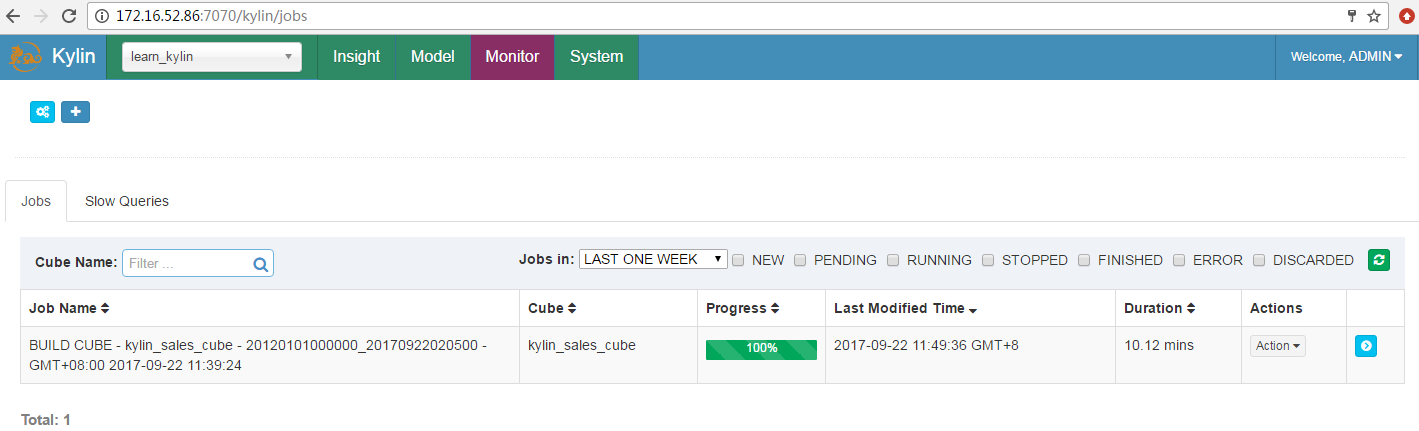
- Cube构建成功,状态变为READY
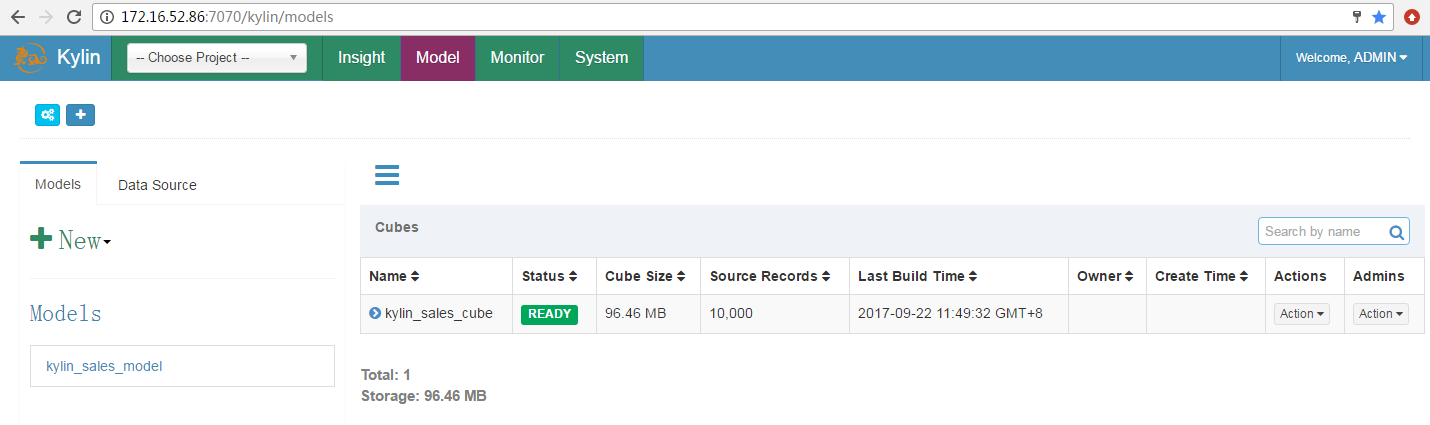
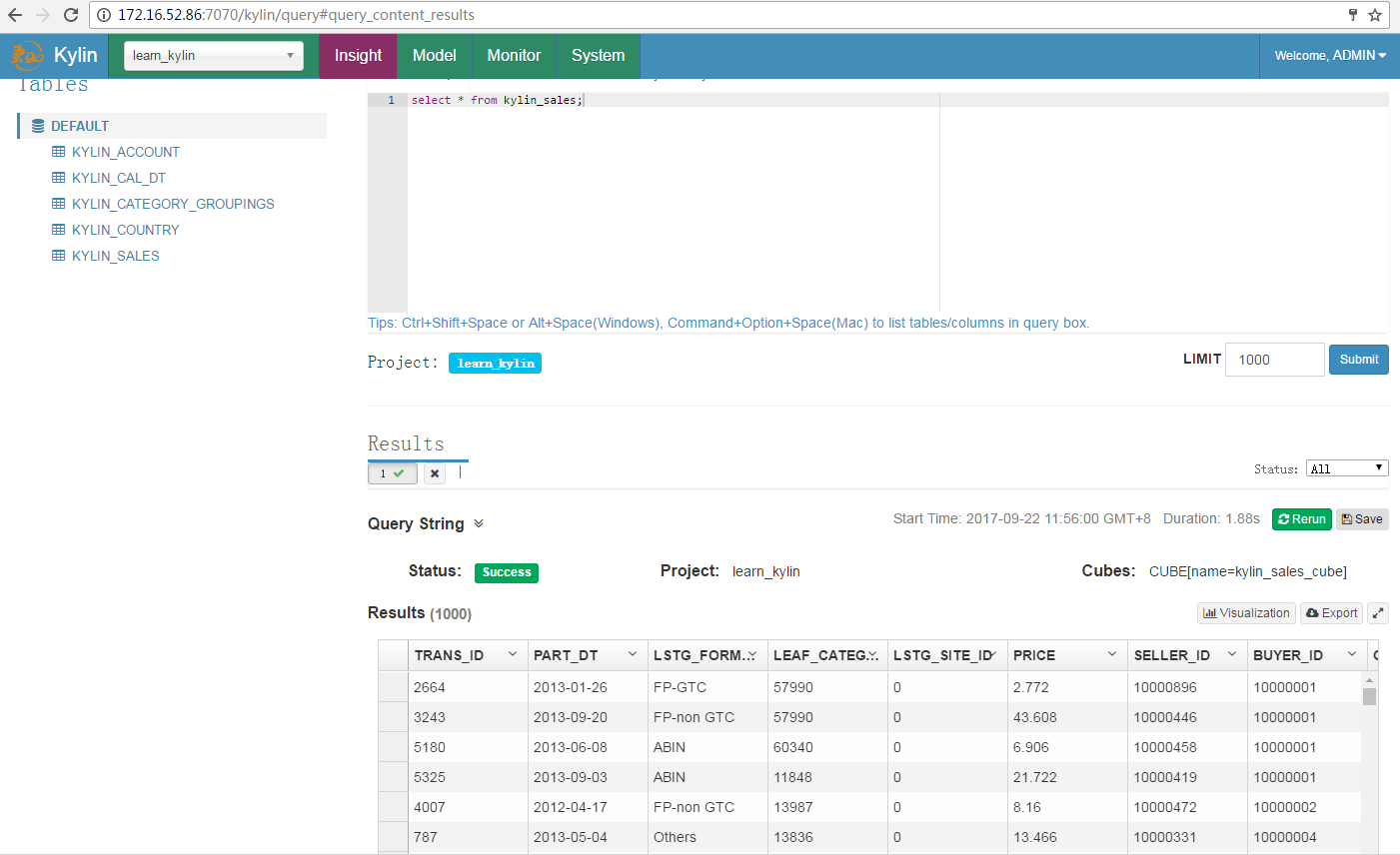
查询表数据¶
- 在Insight页面执行查询
Streaming Sample用例,Kafka普通模式¶
参考官方网站http://kylin.apache.org/docs30/tutorial/kylin_sample.html

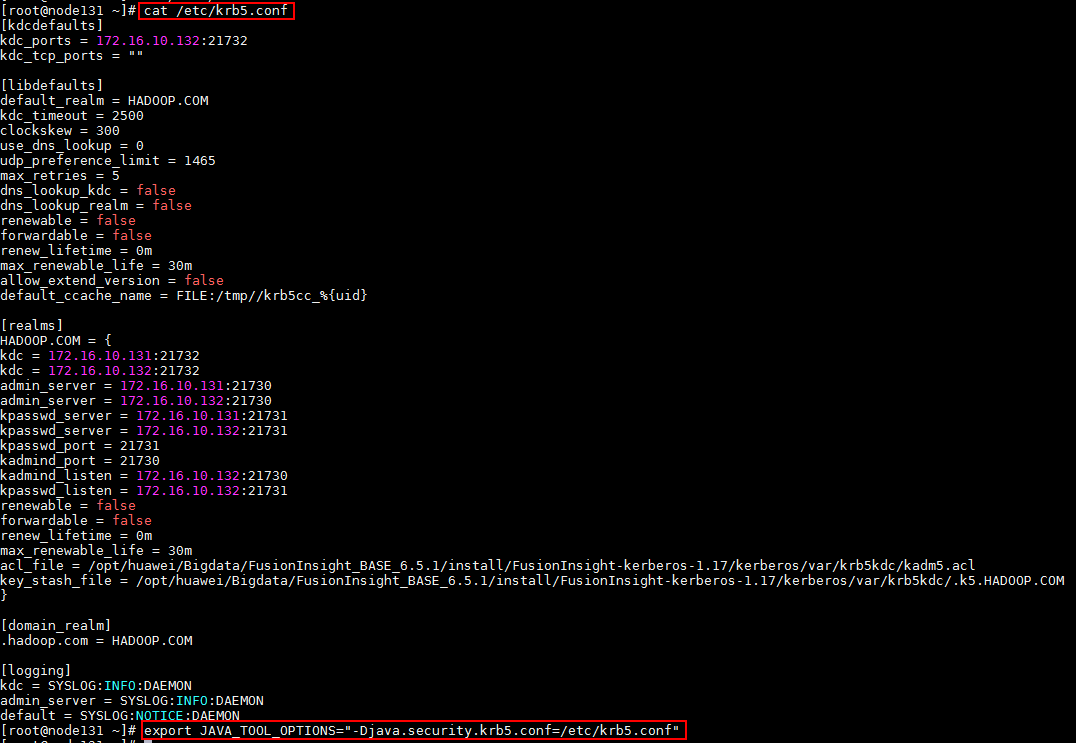
- (重要)首先下载集群认证文件krb5.conf, 登陆对接集群节点,将下载下来有效的krb5.conf文件放置到集群各个节点的/etc/路径下,完成后使用命令
export JAVA_TOOL_OPTIONS="-Djava.security.krb5.conf=/etc/krb5.conf"加载认证参数
下图以其中一个节点为例,其余各节点参考相同命令
- 停止之前运行的Kylin任务,使用如下命令引入已安装的各组件客户端位置
``` export HIVE_CONF=/opt/135_651armhdclient/hadoopclient/Hive/config export HCAT_HOME=/opt/135_651armhdclient/hadoopclient/Hive/HCatalog export KAFKA_HOME=/opt/135_651armhdclient/hadoopclient/Kafka/kafka ````
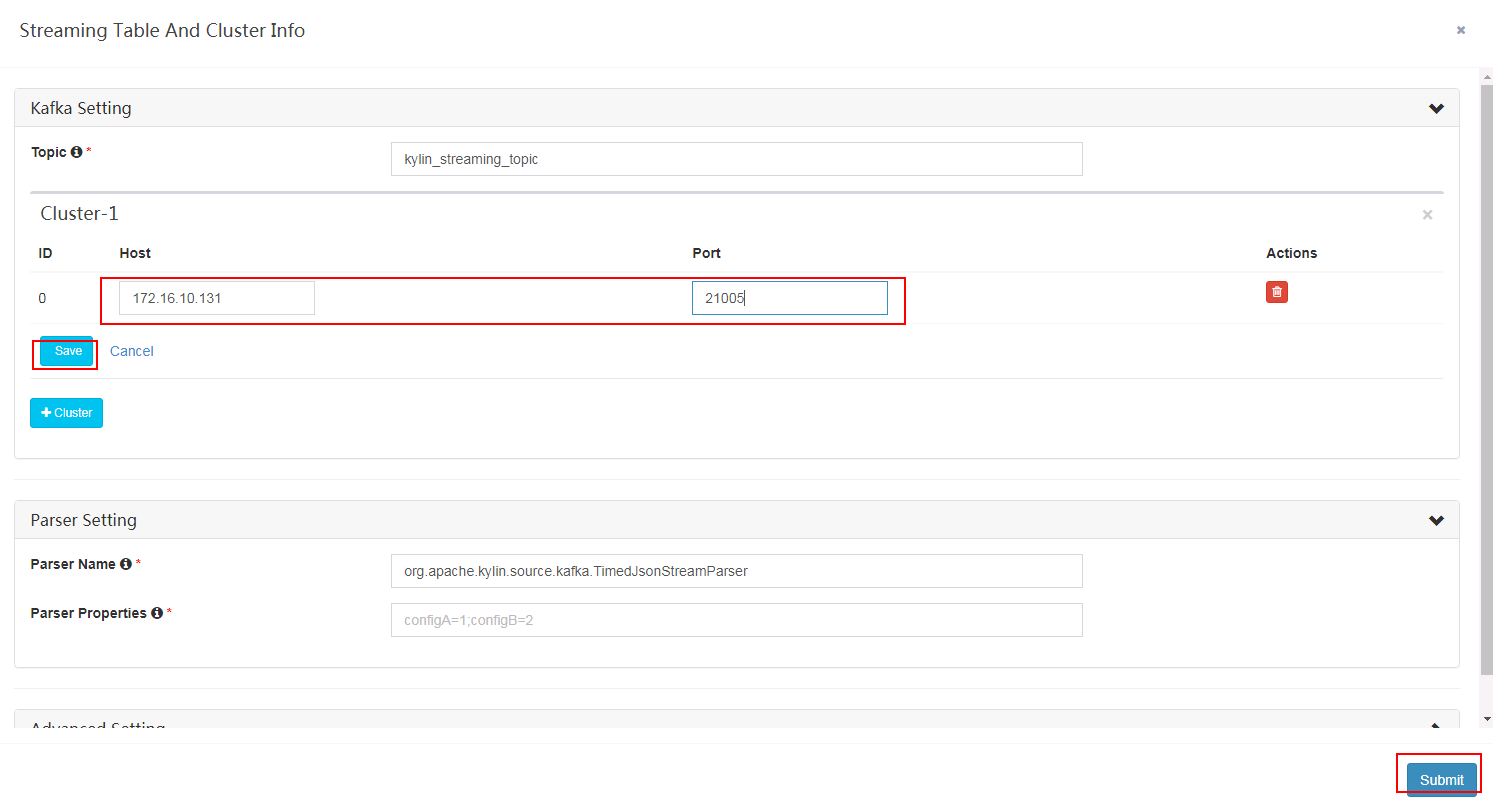
- 到kylin webUI的Model -> Data Source -> 选中表KYLIN_STREAMING_TABLE -> 选择Streaming Cluster -> 点击Edit
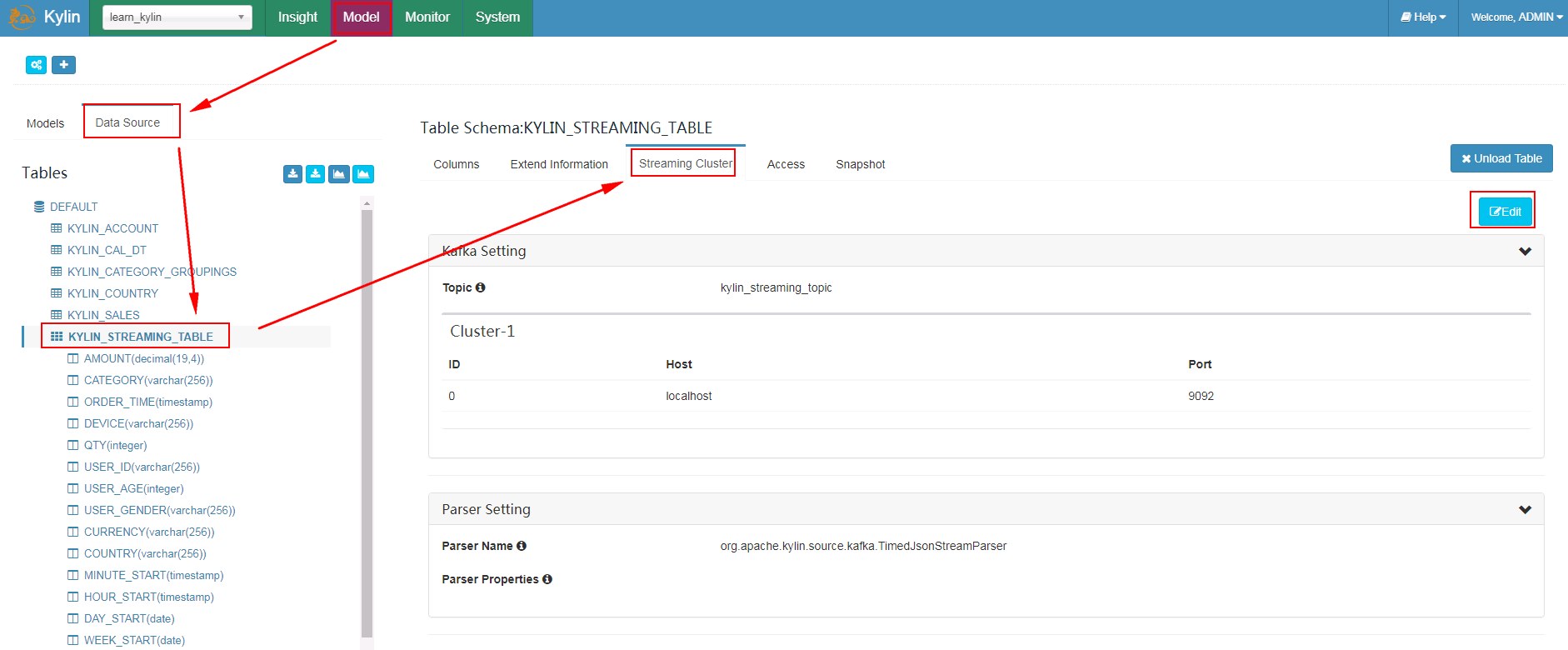
- 填写对应集群kafka连接信息,点击save保存后,在点击submit
- 登陆kylin安装主机后台,修改bin目录下的sample-streaming.sh文件
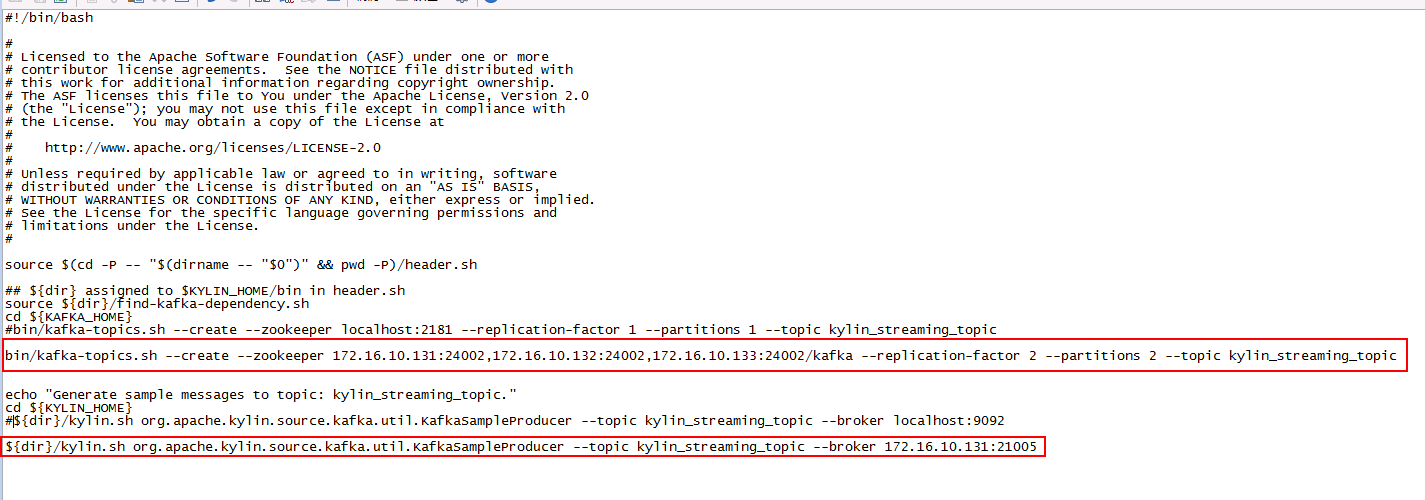
- 登陆后台使用命令
bin/sample-streaming.sh启动任务
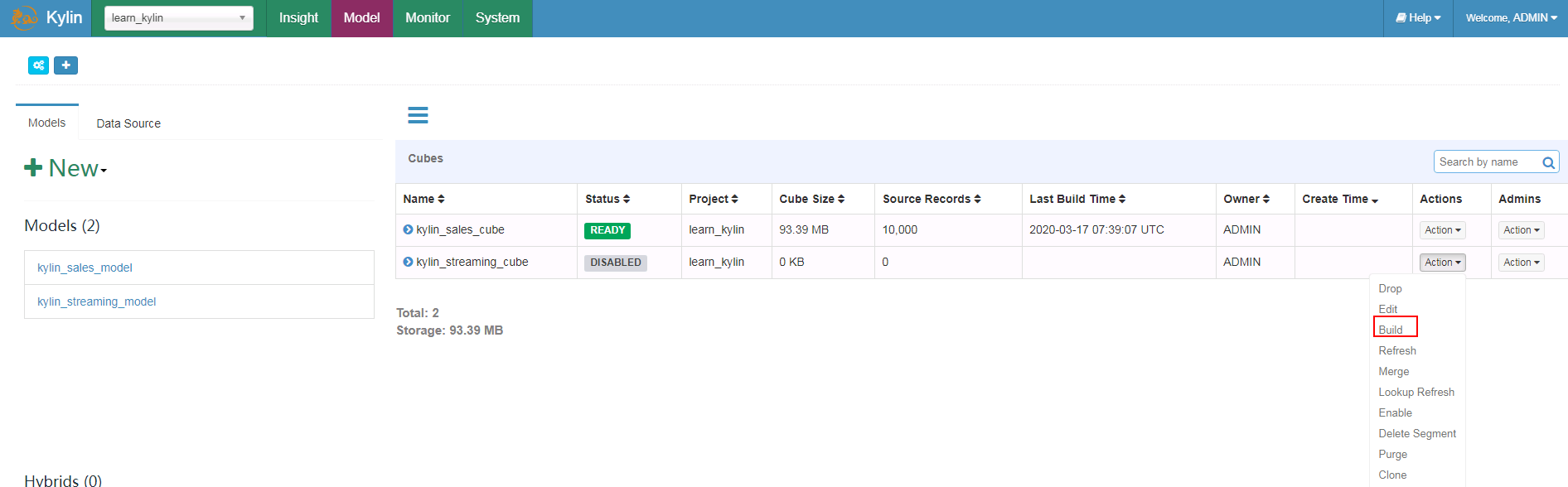
- 回到Model,选择kylin_streaming_cube,点击Build
- 登陆Monitor界面检查
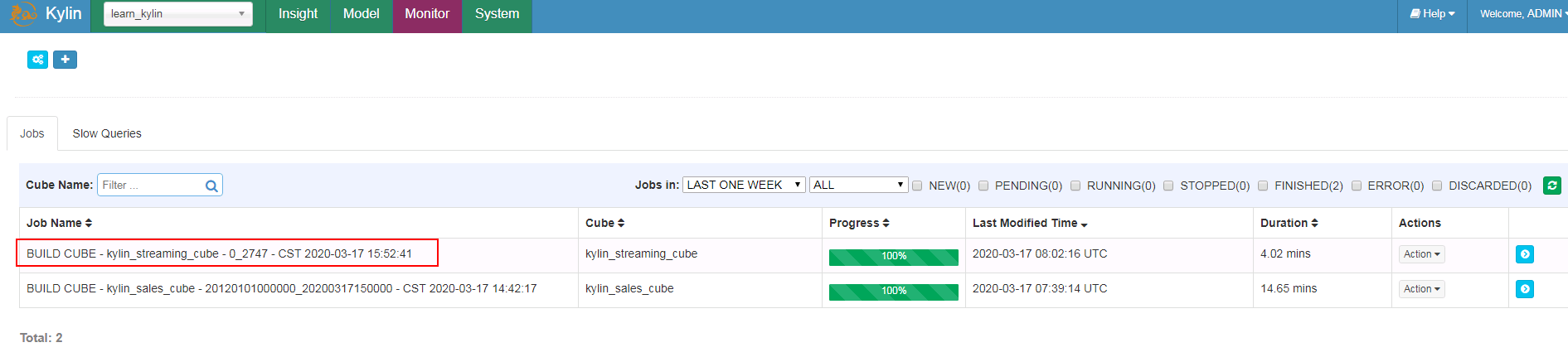
- 登陆Model界面检查
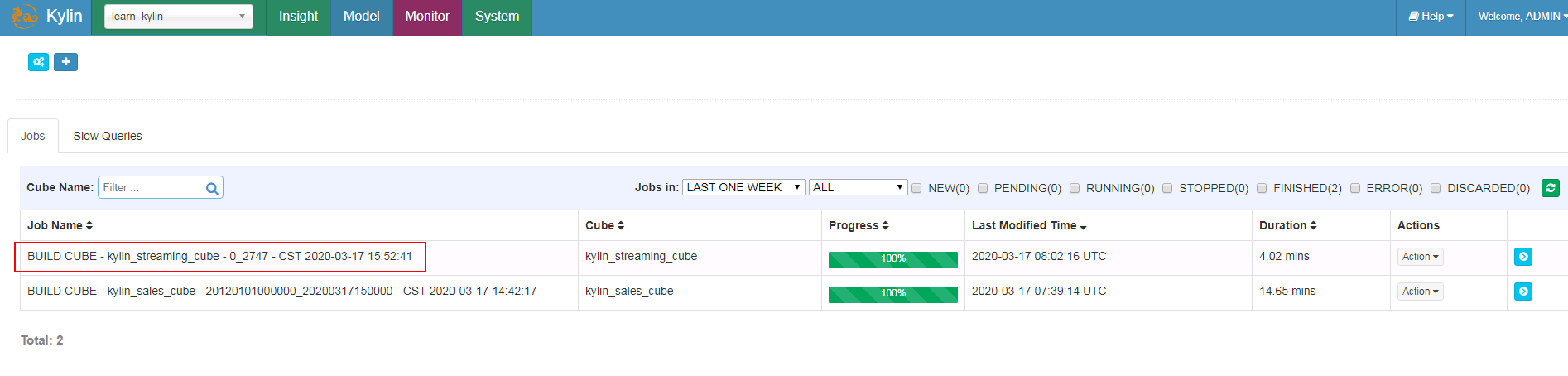
- 登陆Insight界面输入SQL语句查询
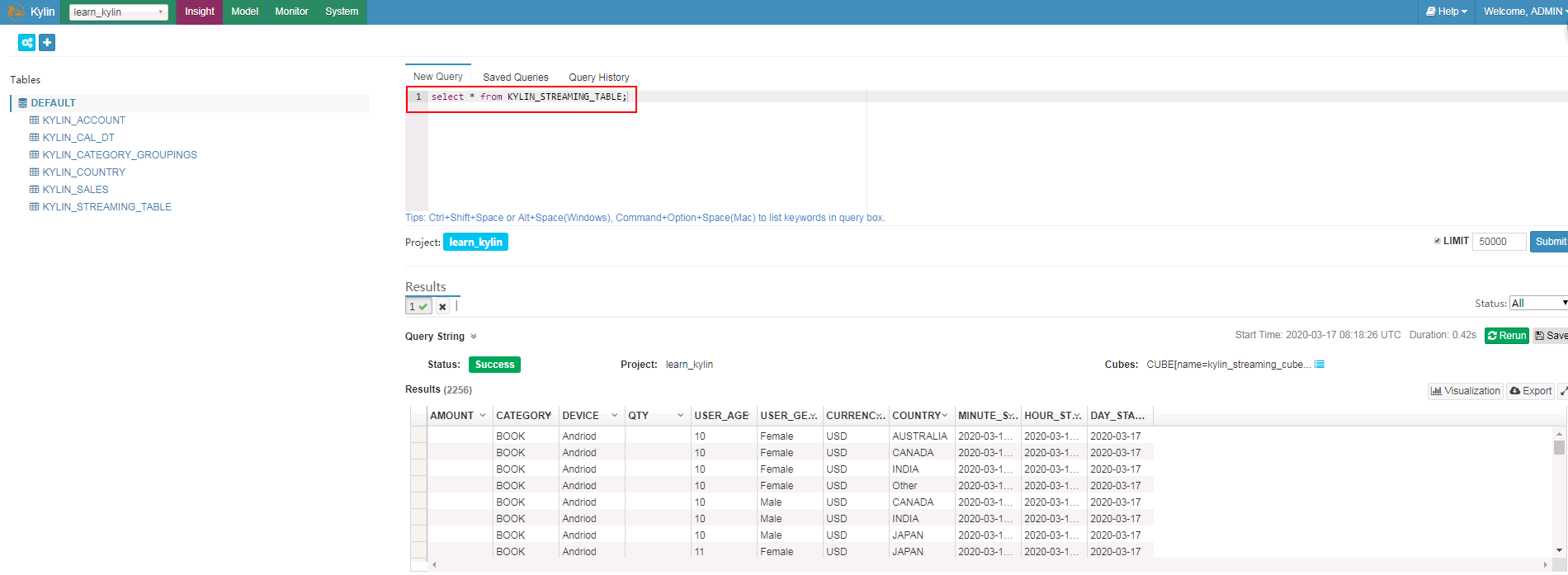
用spark构建cube用例¶
参考Kylin官方文档:http://kylin.apache.org/docs30/tutorial/cube_spark.html
- 停止之前运行的Kylin任务,使用如下命令引入已安装的各组件客户端位置
``` export HIVE_CONF=/opt/135_651armhdclient/hadoopclient/Hive/config export HCAT_HOME=/opt/135_651armhdclient/hadoopclient/Hive/HCatalog export KAFKA_HOME=/opt/135_651armhdclient/hadoopclient/Kafka/kafka export SPARK_HOME=/opt/135_651armhdclient/hadoopclient/Spark2x/spark ````
- (可选)新建路径
/opt/kylin/apache-kylin-3.0.1-bin-hbase1x/spark/jars,使用如下命令将已安装的Spark2x客户端的jar包拷贝到该路径下,并且删除hadoop开头的jar包
cp /opt/135_651armhdclient/hadoopclient/Spark2x/spark/jars/*.jar /opt/kylin/apache-kylin-3.0.1-bin-hbase1x/spark/jars/
rm -rf hadoop-*
-
启动Kylin,登陆web UI
-
选择kylin_sales_cube点Clone, 将新的cube重命名为kylin_sales_cube_clone_Spark2x
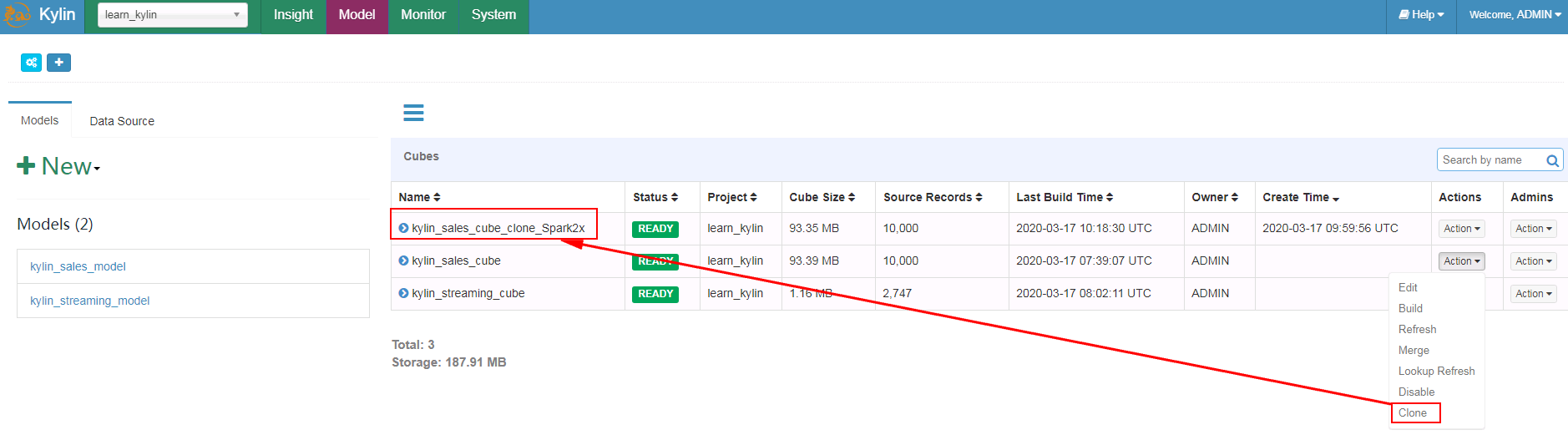
- 选择kylin_sales_cube_clone_Spark2x,在Actions下选择Edit
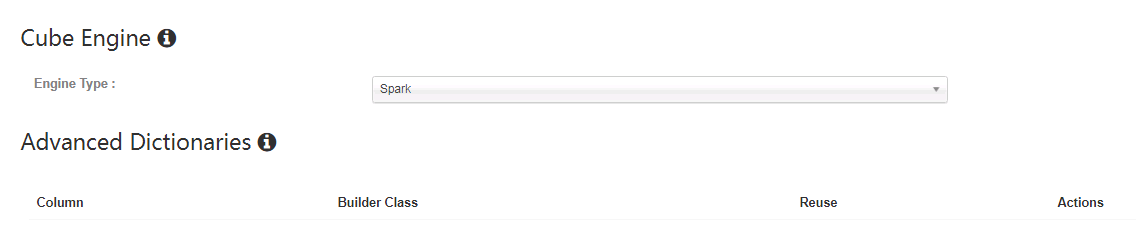
在Advanced Setting下将Cube Engine选成Spark
在Configuration Overwrites检查参数
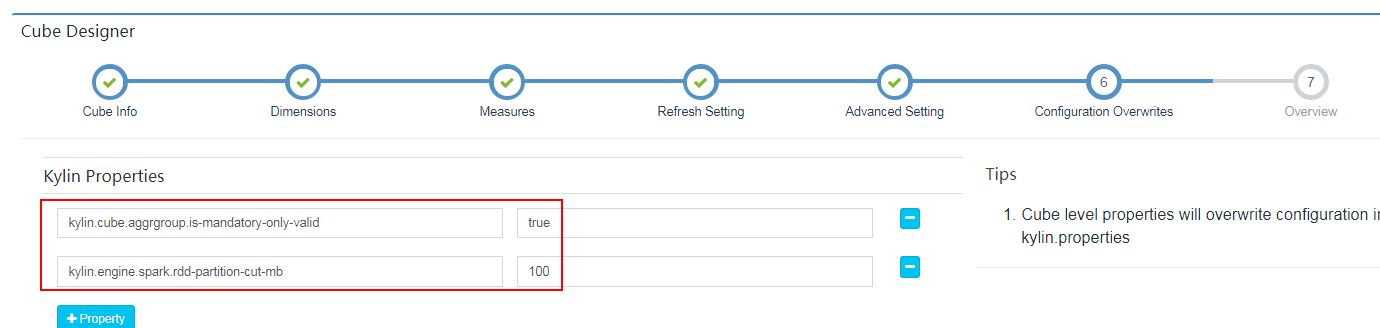
保存
-
Build新创建的kylin_sales_cube_clone_Spark2x
-
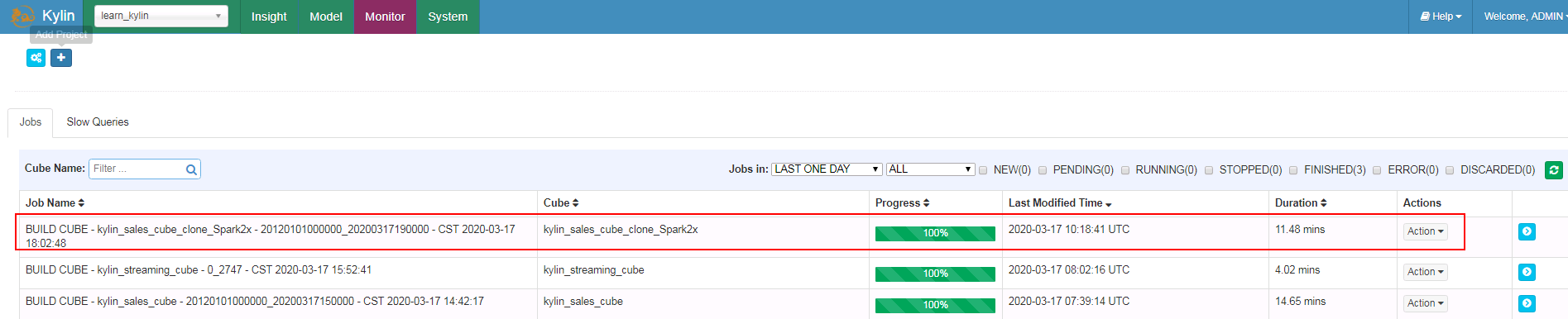
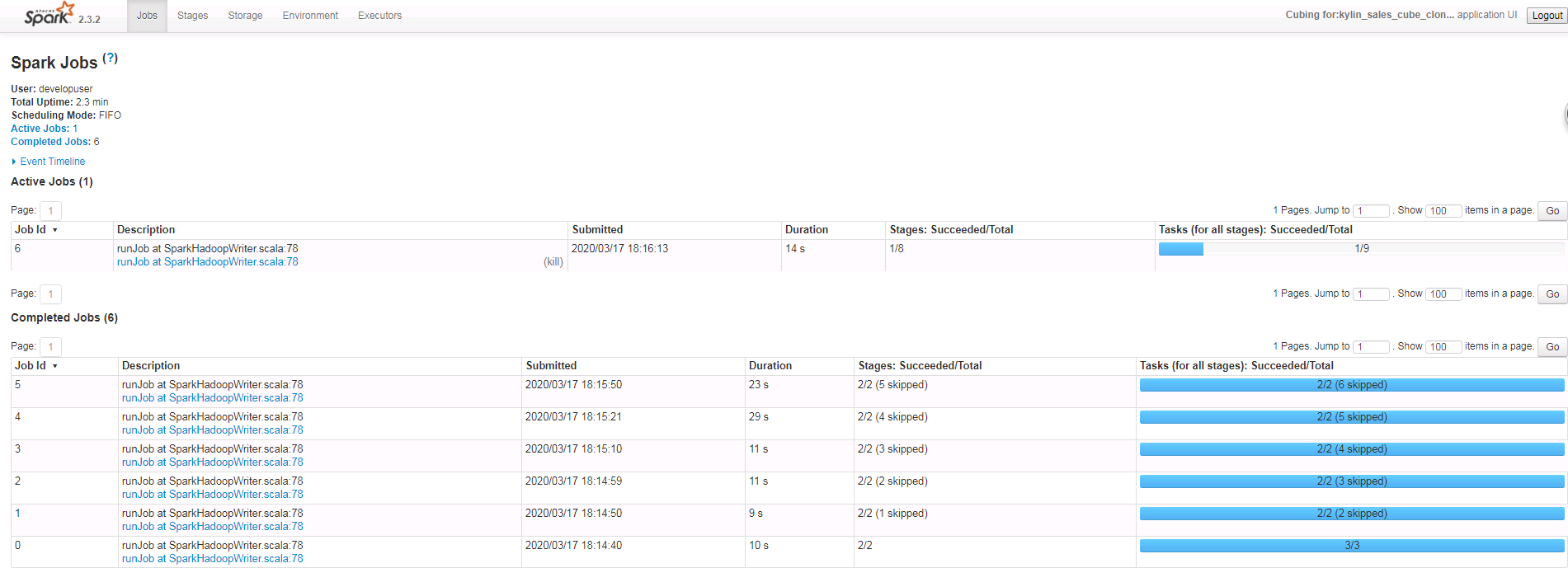
在Monitor下检查作业情况
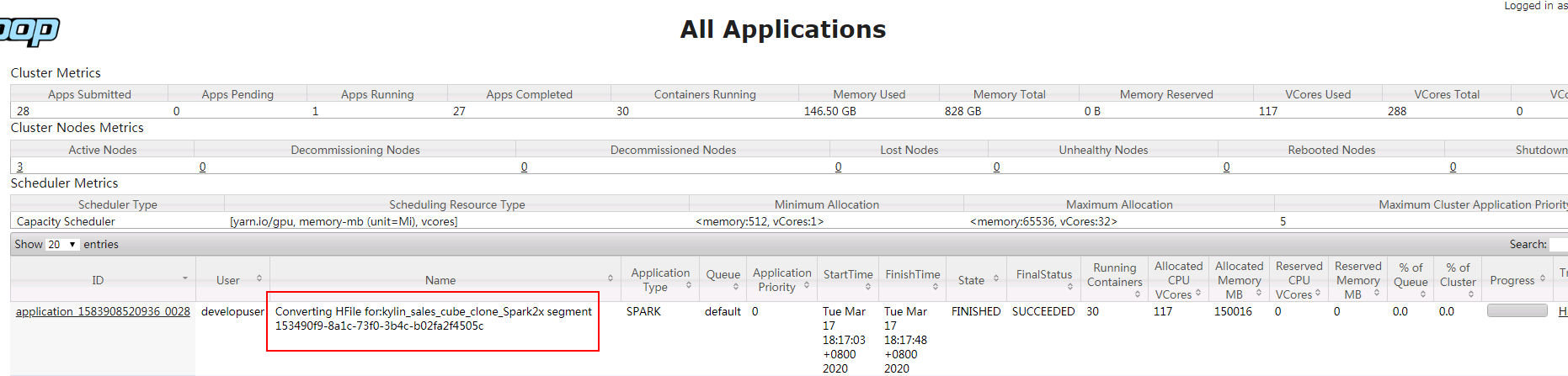
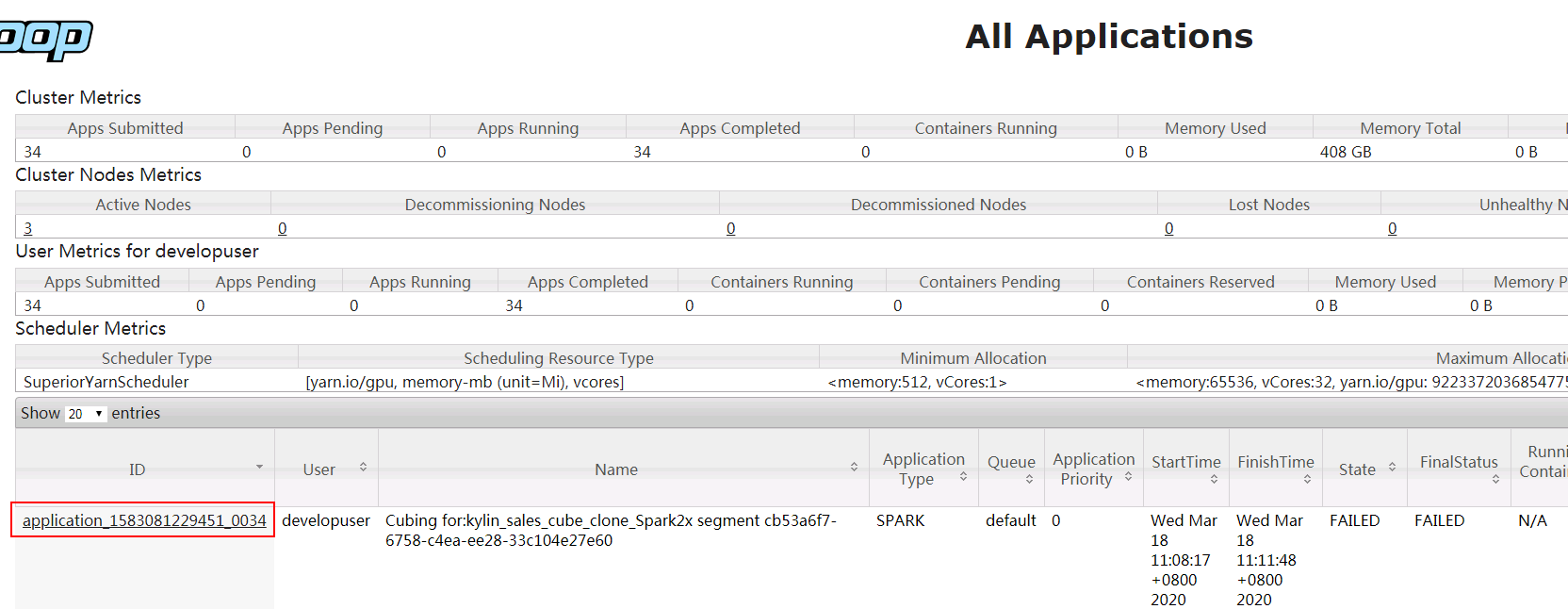
- 可登陆对接集群yarn查看作业情况:
- 登陆Model界面检查

- 登陆Insight界面输入SQL语句查询
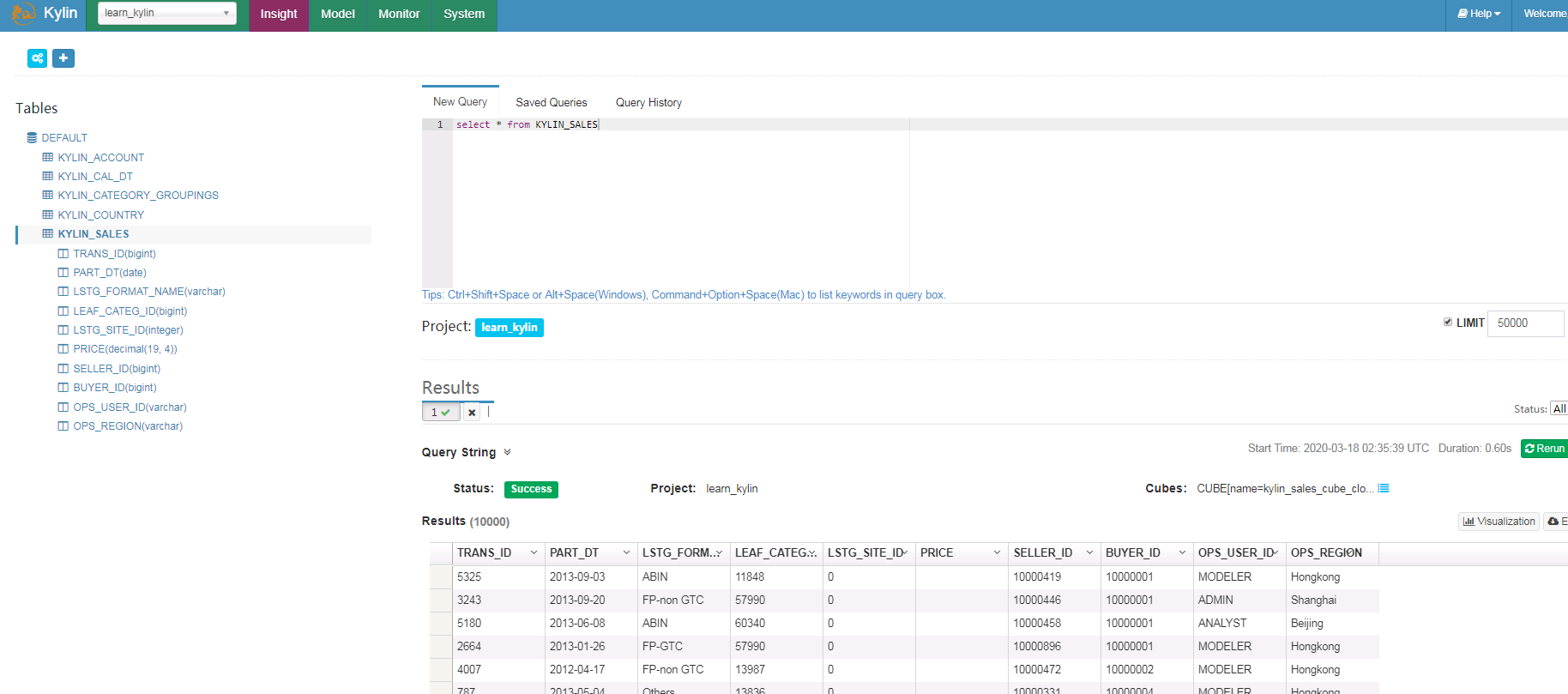
FAQ¶
问题1: 在做bin/sample.sh之后再build cube的时候,第一步遇到报错:
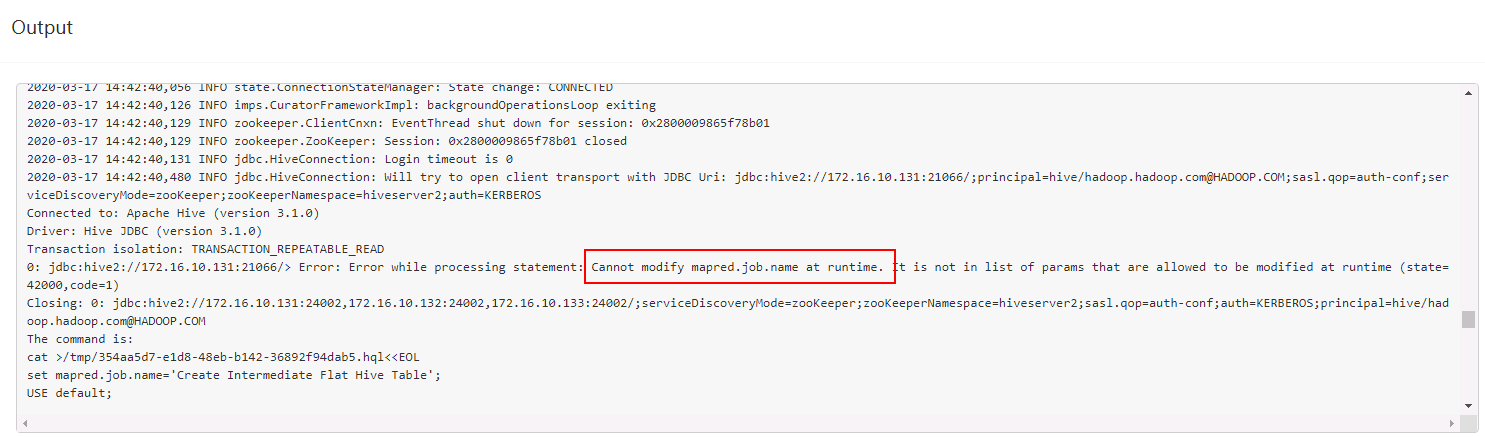
问题原因:权限没加够,参考之前的在hive加权限:
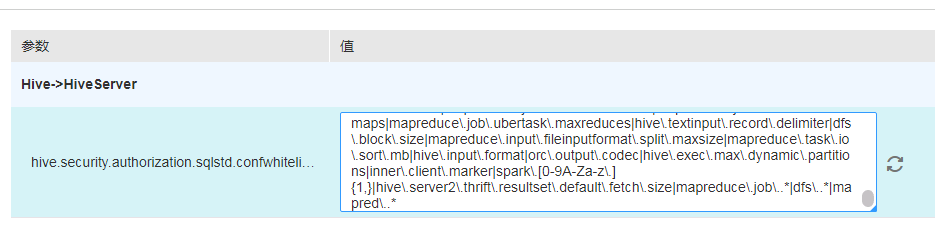
增加|mapred\..*,同步该配置后重启hive服务问题解决
问题2: 在《用spark构建cube用例》这一节中,build作业之后在Monitor查看任务失败

错误卡在第7步
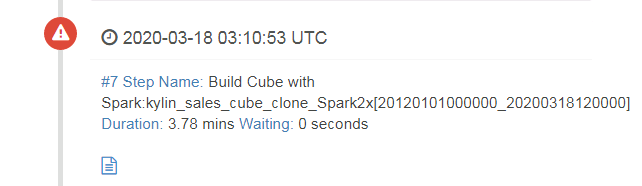
登陆对接集群YARN查看失败任务日志:
在container下查看具体报错日志日志:
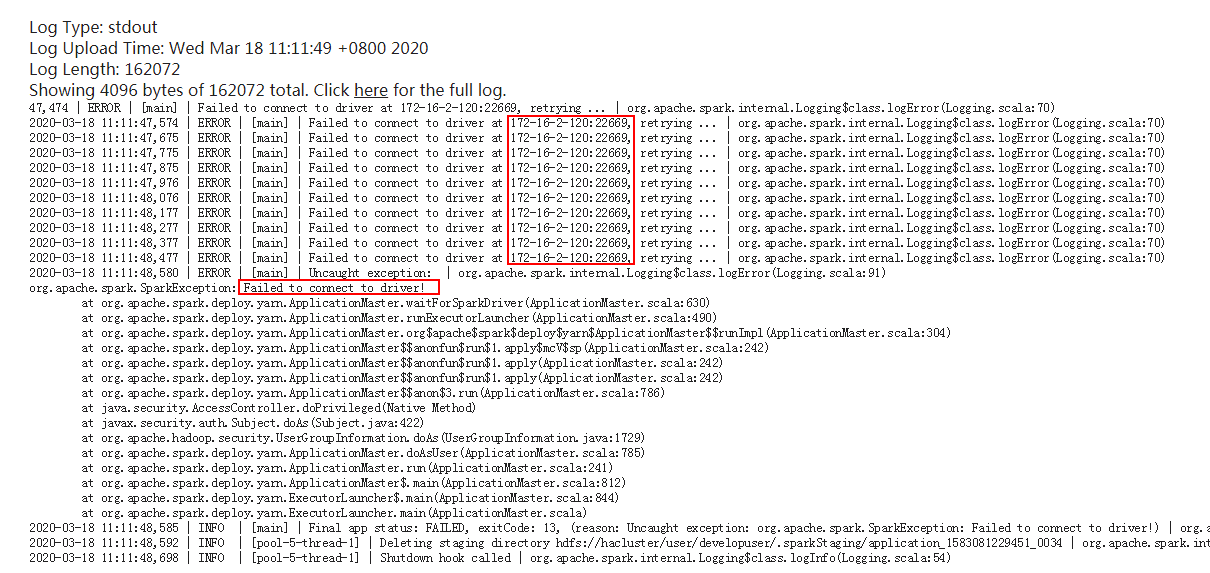
解决办法:将Kylin主机名 172-16-2-120增加到对接集群的/etc/hosts配置文件下重新运行该任务问题解决