RapidMiner对接FusionInsight¶
适用场景¶
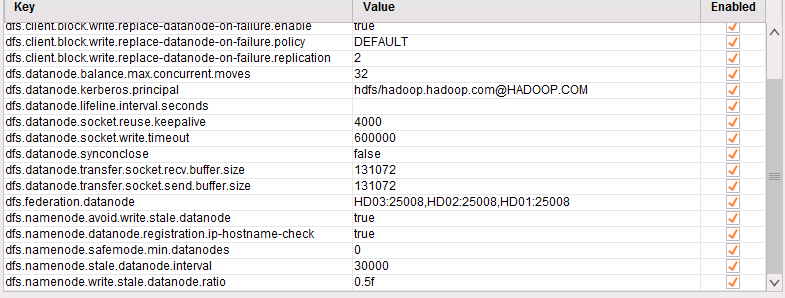
Rapidminer Studio 8.2.001 ↔ FusionInsight HD V100R002C80SPC200 (HDFS/Hive/MapReduce/Spark)
准备工作¶
- 下载安装RapidMiner Studio, 当前最新版本为8.2.001,下载地址 https://rapidminer.com/
-
安装完成后在主界面顶部菜单栏选择
Extensions->Marketplace,搜索radoop,安装后重启rapidminer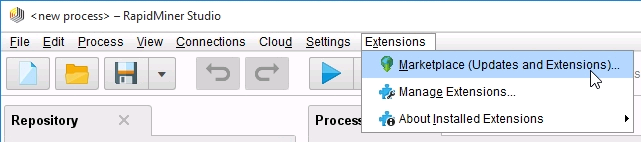
-
修改本地host文件,路径为C:\Windows\System32\drivers\etc,加入集群各个节点IP与主机名对应关系,保存文件。
-
设置Kerberos的配置文件
在FusionInsight Manager创建一个角色与“人机”用户,具体请参见《FusionInsight HD 管理员指南》的创建用户章节。角色根据业务需要授予Spark,Hive,HDFS的访问权限,并将用户加入角色。例如,创建用户“developuser”并下载对应的keytab文件user.keytab以及krb5.conf文件。
-
准备FusionInsight客户端配置文件以及jar包
- 在集群的Manager中,选择服务->下载客户端->完整客户端
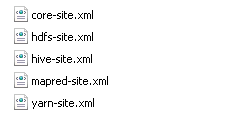
- 解压后,进入HDFS,Hive,Yarn组件的config目录,找到如下的配置文件,复制到一个文件夹里,例如命名为config。
- 打开
yarn-site.xml,删除以下参数配置<property> <name>audit.service.name</name> <value>Yarn</value> </property> - 进入Spark组件的Jar包目录“\FusionInsight_Services_ClientConfig\Spark2x\FusionInsight-Spark2x-2.1.0.tar.gz\spark\jars”,将所有jar包复制出来,保存在本机某目录下,例如
C:/jars。
集群配置¶
-
配置UDP端口绑定
- 下载安装UDP端口绑定工具uredir,下载地址https://github.com/troglobit/uredir
- 编译安装完成后,分别上传至KDC服务所在的主备节点(可在krb5.conf文件中查看),进入uredir执行文件所在目录,执行以下命令进行端口绑定,其中IP为所在节点IP
./uredir IP:88 IP:21732
-
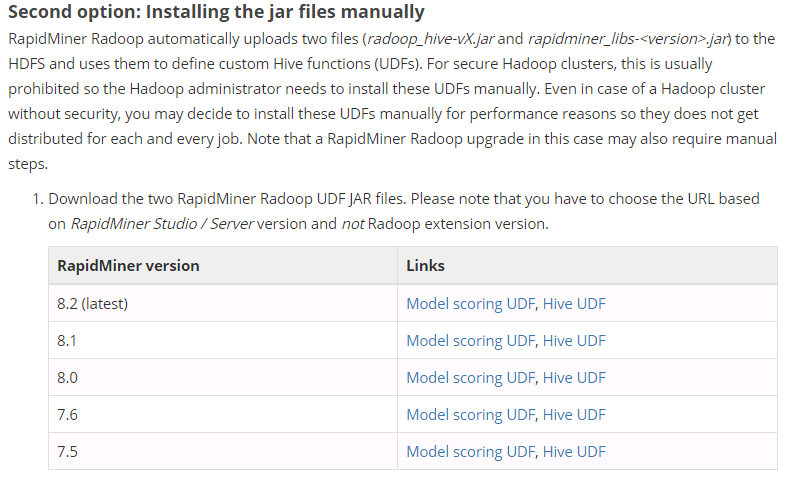
配置Radoop依赖jar包
- 在Radoop文档中心,下载Radoop依赖jar包,下载地址https://docs.rapidminer.com/latest/radoop/installation/operation-and-maintenance.html,下载与安装的RapidMiner版本对应的jar包。
-
将jar包上传至集群每个节点相同的路径下,例如/usr/local/lib/radoop/
-
在集群HiveServer所在节点,分别上传Radoop的jar包至以下路径,并修改所有者和执行权限
- Hive服务端的lib路径"/opt/huawei/Bigdata/FusionInsight_HD_V100R002C80SPC200/install/FusionInsight-Hive-1.3.0/hive-1.3.0/lib",
- Mapreduce服务端的lib路径:"/opt/huawei/Bigdata/FusionInsight_HD_V100R002C80SPC200/install/FusionInsight-Hadoop-2.7.2/hadoop/share/hadoop/mapreduce/lib"
* 在FusionInsight Manager 界面添加Hive白名单配置cd /opt/huawei/Bigdata/FusionInsight_HD_V100R002C80SPC200/install/FusionInsight-Hive-1.3.0/hive-1.3.0/lib chown omm:wheel radoop_hive-v4.jar chown omm:wheel rapidminer_libs-8.2.0.jar chmod 700 radoop_hive-v4.jar chmod 700 rapidminer_libs-8.2.0.jar cd /opt/huawei/Bigdata/FusionInsight_HD_V100R002C80SPC200/install/FusionInsight-Hadoop-2.7.2/hadoop/share/hadoop/mapreduce/lib chown omm:ficommon radoop_hive-v4.jar chown omm:ficommon rapidminer_libs-8.2.0.jar chmod 750 radoop_hive-v4.jar chmod 750 rapidminer_libs-8.2.0.jar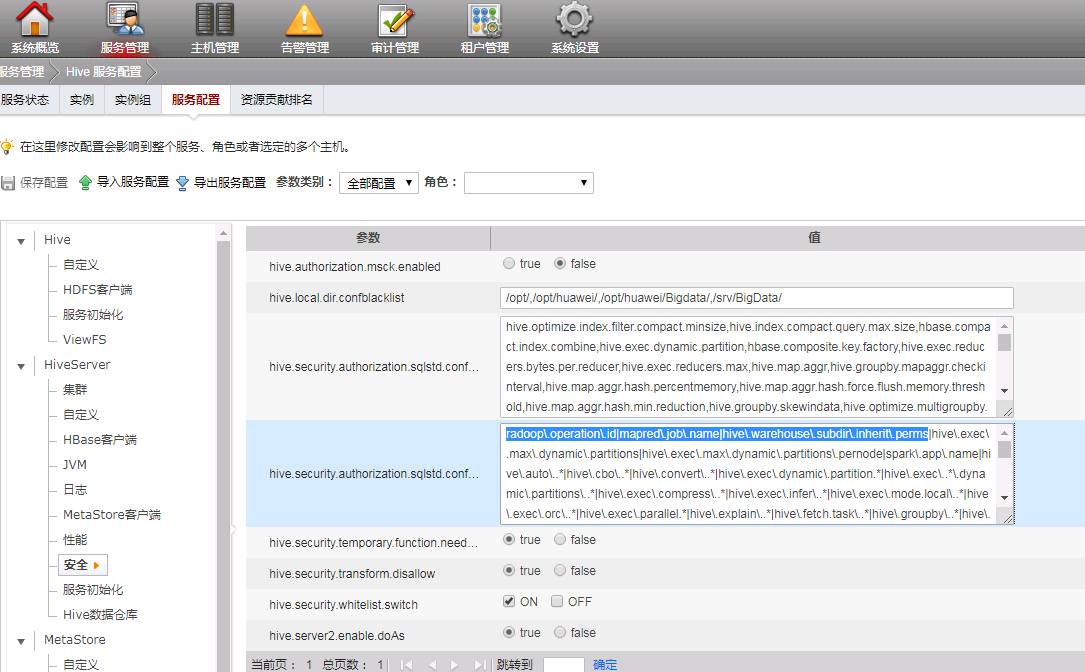 需要以
需要以radoop\.operation\.id|mapred\.job\.name|hive\.warehouse\.subdir\.inherit\.perms|hive\.exec\.max\.dynamic\.partitions|hive\.exec\.max\.dynamic\.partitions\.pernode|spark\.app\.name|分割 * 保存配置后,重启HiveServer -
创建Radoop UDF函数
-
在主节点执行如下命令:
输入developuser用户密码,执行beeline,进入Hive#cd /opt/hadoopclient #source bigdata_env #kinit developuser -
Hive中创建数据库,例如创建数据库rapidminer,执行以下命令:
create database rapidminer; use rapidminer; DROP FUNCTION IF EXISTS r3_add_file; DROP FUNCTION IF EXISTS r3_apply_model; DROP FUNCTION IF EXISTS r3_correlation_matrix; DROP FUNCTION IF EXISTS r3_esc; DROP FUNCTION IF EXISTS r3_gaussian_rand; DROP FUNCTION IF EXISTS r3_greatest; DROP FUNCTION IF EXISTS r3_is_eq; DROP FUNCTION IF EXISTS r3_least; DROP FUNCTION IF EXISTS r3_max_index; DROP FUNCTION IF EXISTS r3_nth; DROP FUNCTION IF EXISTS r3_pivot_collect_avg; DROP FUNCTION IF EXISTS r3_pivot_collect_count; DROP FUNCTION IF EXISTS r3_pivot_collect_max; DROP FUNCTION IF EXISTS r3_pivot_collect_min; DROP FUNCTION IF EXISTS r3_pivot_collect_sum; DROP FUNCTION IF EXISTS r3_pivot_createtable; DROP FUNCTION IF EXISTS r3_score_naive_bayes; DROP FUNCTION IF EXISTS r3_sum_collect; DROP FUNCTION IF EXISTS r3_which; DROP FUNCTION IF EXISTS r3_sleep; CREATE FUNCTION r3_add_file AS 'eu.radoop.datahandler.hive.udf.GenericUDFAddFile'; CREATE FUNCTION r3_apply_model AS 'eu.radoop.datahandler.hive.udf.GenericUDTFApplyModel'; CREATE FUNCTION r3_correlation_matrix AS 'eu.radoop.datahandler.hive.udf.GenericUDAFCorrelationMatrix'; CREATE FUNCTION r3_esc AS 'eu.radoop.datahandler.hive.udf.GenericUDFEscapeChars'; CREATE FUNCTION r3_gaussian_rand AS 'eu.radoop.datahandler.hive.udf.GenericUDFGaussianRandom'; CREATE FUNCTION r3_greatest AS 'eu.radoop.datahandler.hive.udf.GenericUDFGreatest'; CREATE FUNCTION r3_is_eq AS 'eu.radoop.datahandler.hive.udf.GenericUDFIsEqual'; CREATE FUNCTION r3_least AS 'eu.radoop.datahandler.hive.udf.GenericUDFLeast'; CREATE FUNCTION r3_max_index AS 'eu.radoop.datahandler.hive.udf.GenericUDFMaxIndex'; CREATE FUNCTION r3_nth AS 'eu.radoop.datahandler.hive.udf.GenericUDFNth'; CREATE FUNCTION r3_pivot_collect_avg AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotAvg'; CREATE FUNCTION r3_pivot_collect_count AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotCount'; CREATE FUNCTION r3_pivot_collect_max AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotMax'; CREATE FUNCTION r3_pivot_collect_min AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotMin'; CREATE FUNCTION r3_pivot_collect_sum AS 'eu.radoop.datahandler.hive.udf.GenericUDAFPivotSum'; CREATE FUNCTION r3_pivot_createtable AS 'eu.radoop.datahandler.hive.udf.GenericUDTFCreatePivotTable'; CREATE FUNCTION r3_score_naive_bayes AS 'eu.radoop.datahandler.hive.udf.GenericUDFScoreNaiveBayes'; CREATE FUNCTION r3_sum_collect AS 'eu.radoop.datahandler.hive.udf.GenericUDAFSumCollect'; CREATE FUNCTION r3_which AS 'eu.radoop.datahandler.hive.udf.GenericUDFWhich'; CREATE FUNCTION r3_sleep AS 'eu.radoop.datahandler.hive.udf.GenericUDFSleep';
-
RapidMiner配置¶
- 在RapidMiner中,菜单选择Connections->Manage Radoop Connections
-
在弹出的对话框中选择New Connections->Import Hadoop Configuration Files,选择配置文件所在文件夹,点击Import Configuration
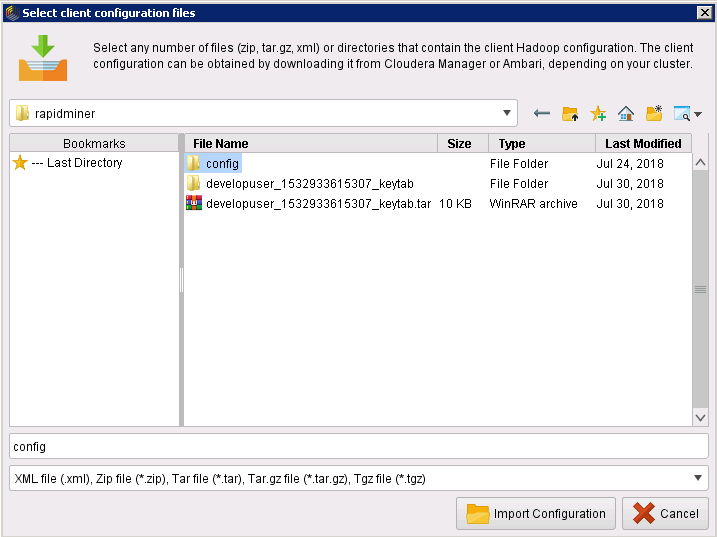
-
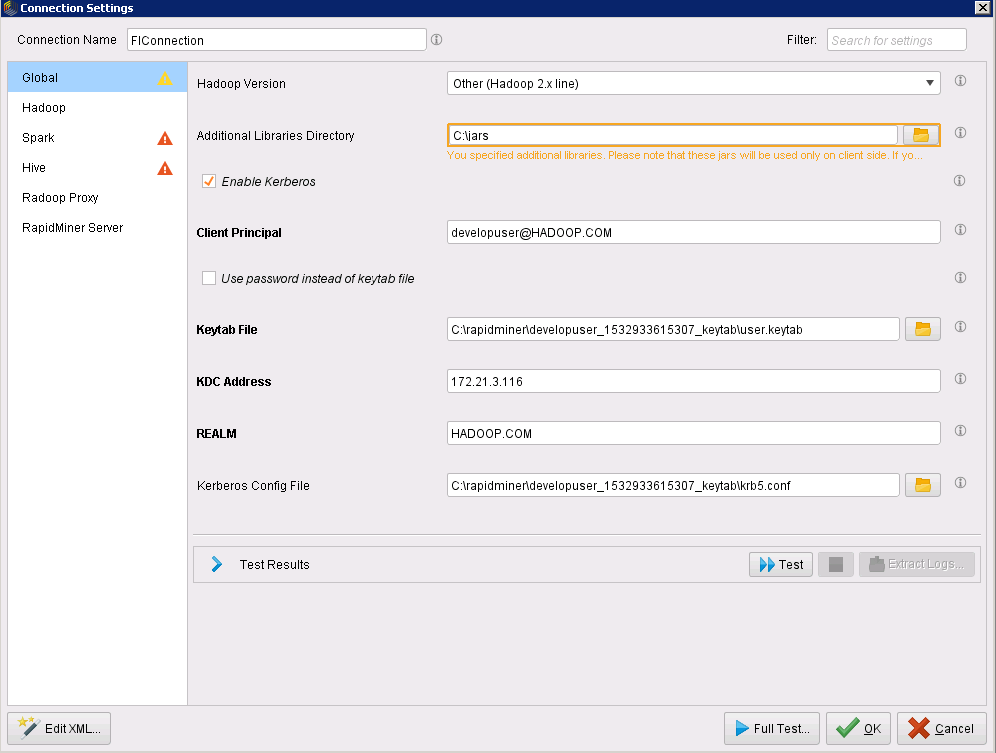
导入成功后点击Next,进入连接配置窗口,根据左侧菜单栏,进行如下填写:
- Global:
- Hadoop Version:Other(Hadoop 2X line)
- Additional Libraries Directory:Spark组件的jars包
- Client Principal: Kerberos用户名@HADOOP.com
- Keytab File: 从Manager下载的keytab文件
- KDC Address: 集群KDC所在服务器IP
- REALM: HADOOP.COM
- Kerberos Config File: 从Manager下载的krb5配置文件
- Hadoop:
-
在左上角搜索框中搜索split,在搜索结果中取消勾选mapreduce.input.fileinputformat.split.maxsize参数
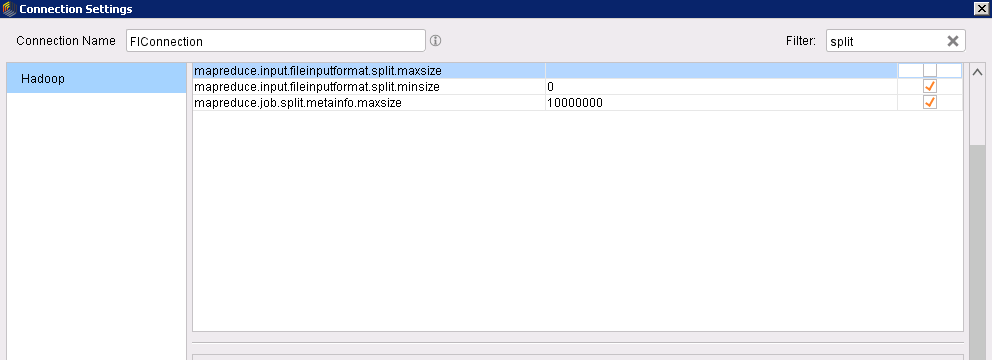
-
搜索classpath,在搜索结果中取消勾选mapreduce.application.classpath参数
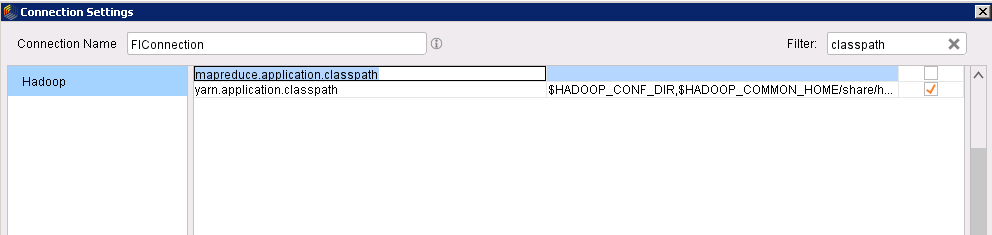
-
Spark:
- Spark Version:Spark2.1
- Spark Archive(or libs)Path: local:///opt/huawei/Bigdata/FusionInsight_Spark2x_V100R002C80SPC200/install/FusionInsight-Spark2x-2.1.0/spark/jars
- Spark Resource Allocation Policy:Static,Default Configuration
-
Advanced Spark Parameters:添加spark.driver.extraJavaOptions和spark.executor.extraJavaOptions两个参数
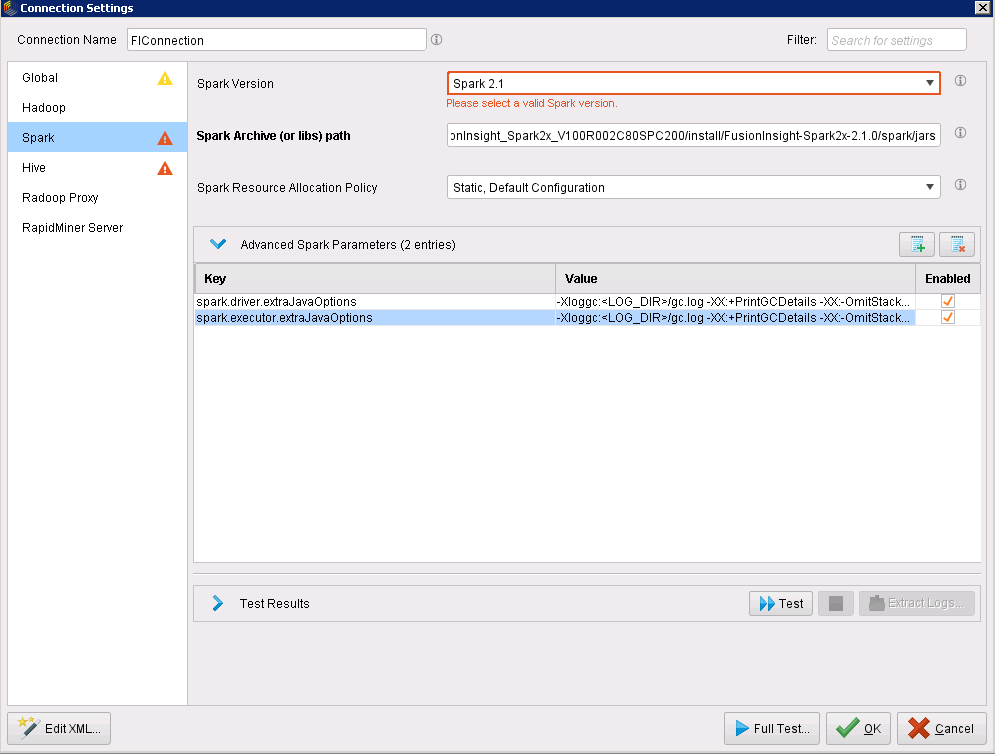
-
参数value在Manager,Services->Spark2X Configuration->所有配置,搜索extraJavaOptions,选择Spark2x->SparkResource2x中的这两个参数值,将其中使用的所有“./”相对路径替换为服务端Spark配置文件所在的绝对路径,例如“/opt/huawei/Bigdata/FusionInsight_Spark2x_V100R002C80SPC200/1_21_SparkResource2x/etc”
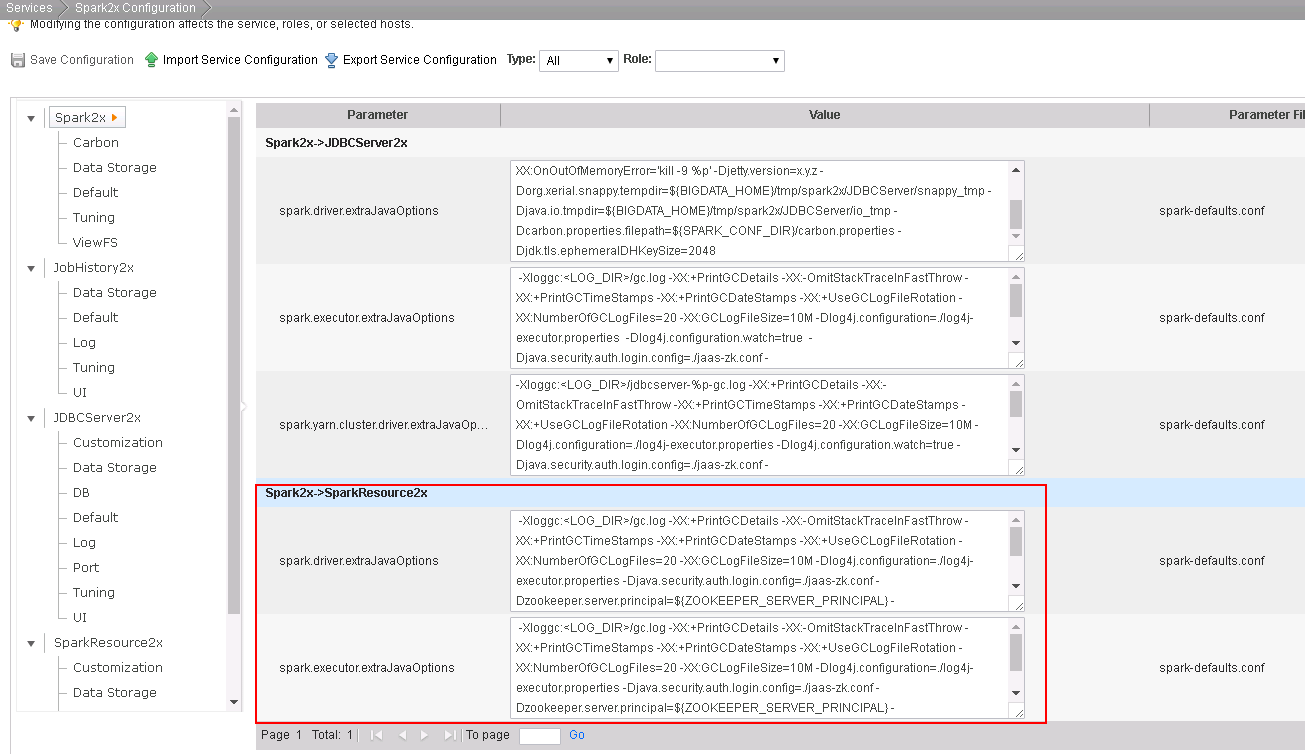
-
Hive:
- Hive Version:Hive Server2
- Hive Server Address:Hive 服务所在节点IP
- Hive Port: 21066
- Database Name: 在Hive中创建的Radoop Function所在的数据库名称
- Customer database for UDFs: 同Database Name
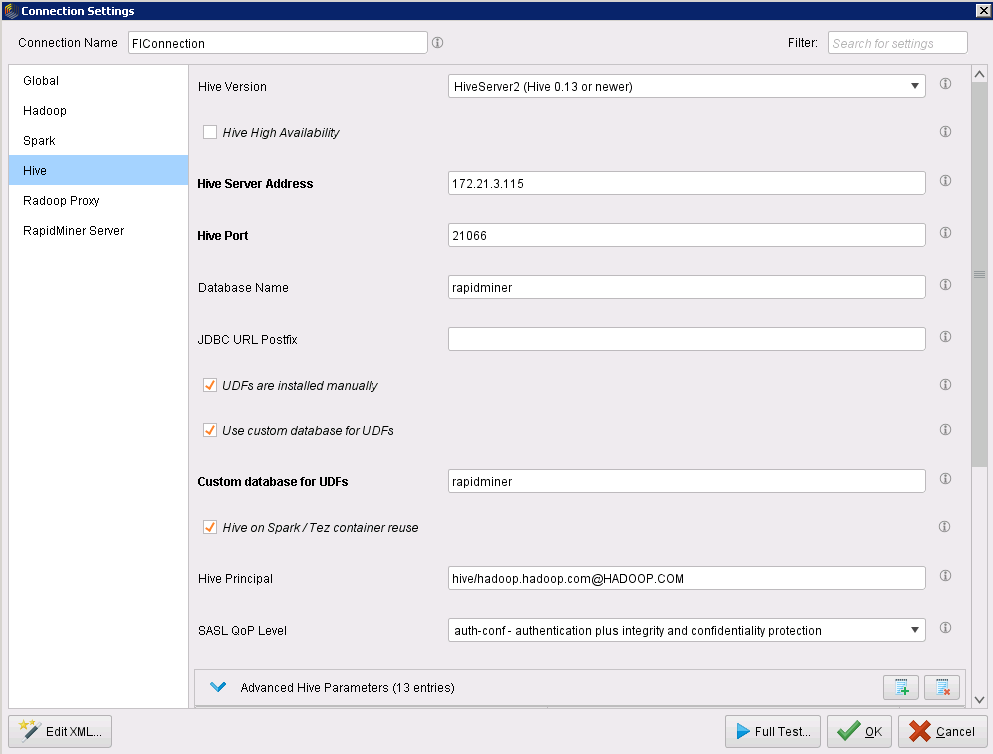
- 点击OK->Proced Anyway->Save
测试连接¶
-
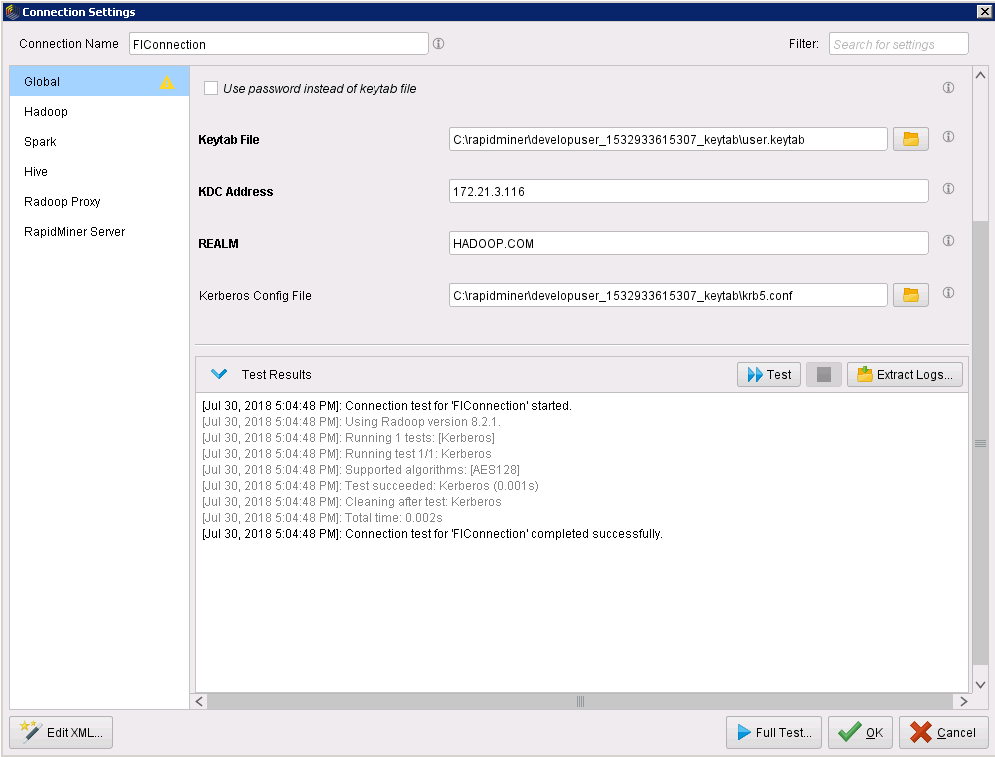
点击Configure,在Global页面,点击Test,Test Results显示如下,表明Global测试成功
-
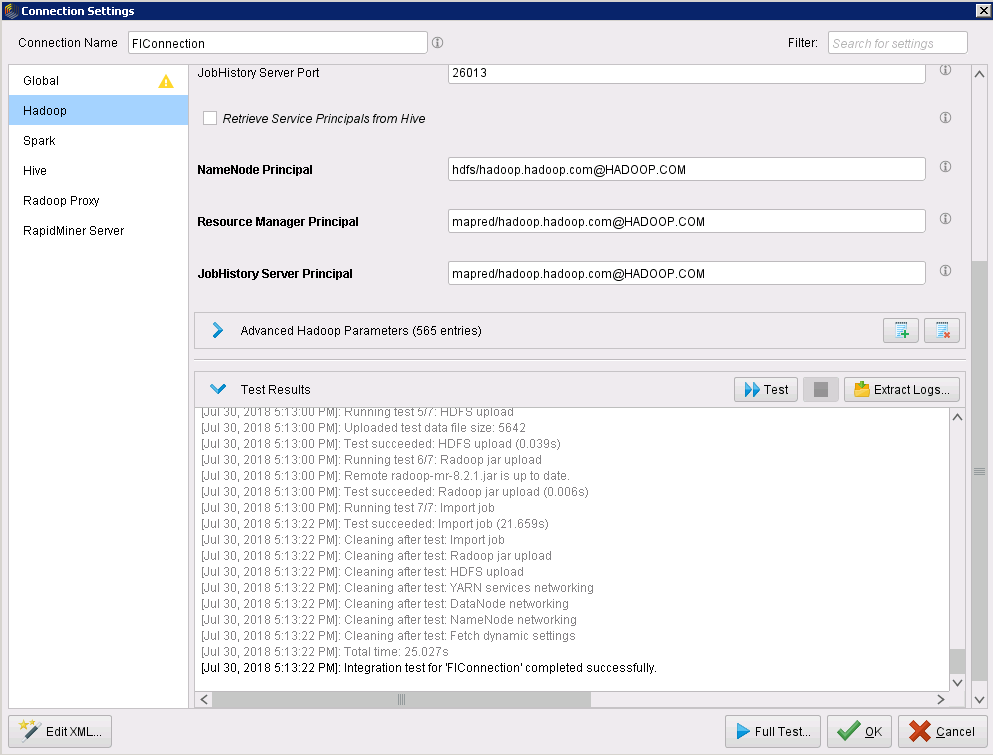
在Hadoop页面,点击Test,Test Results显示如下,表明Hadoop测试成功
-
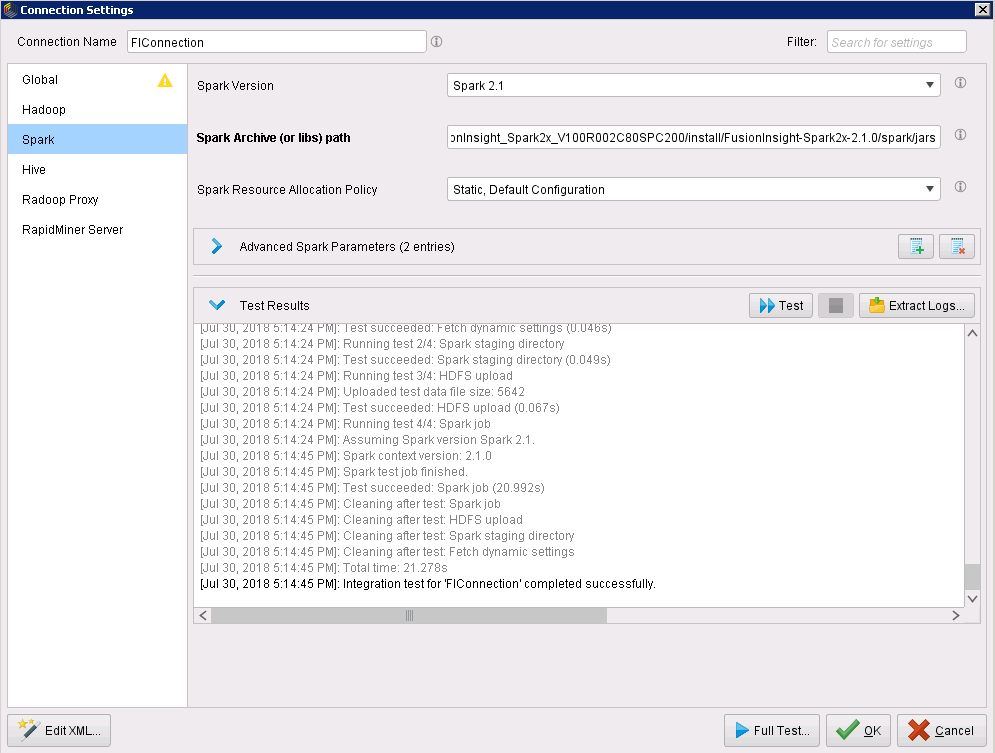
在Spark页面,点击Test,Test Results显示如下,表明Spark测试成功
-
在Hive页面,点击Test,Test Results显示如下,表明Hive测试成功
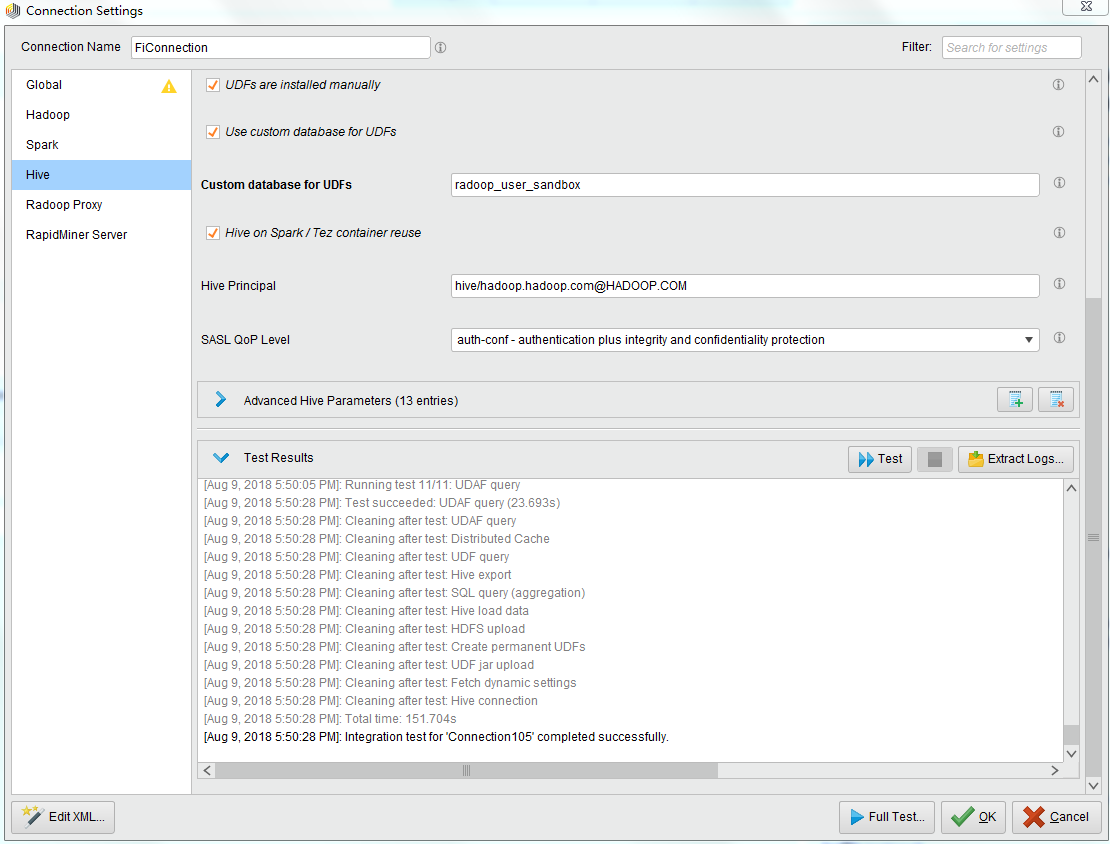
-
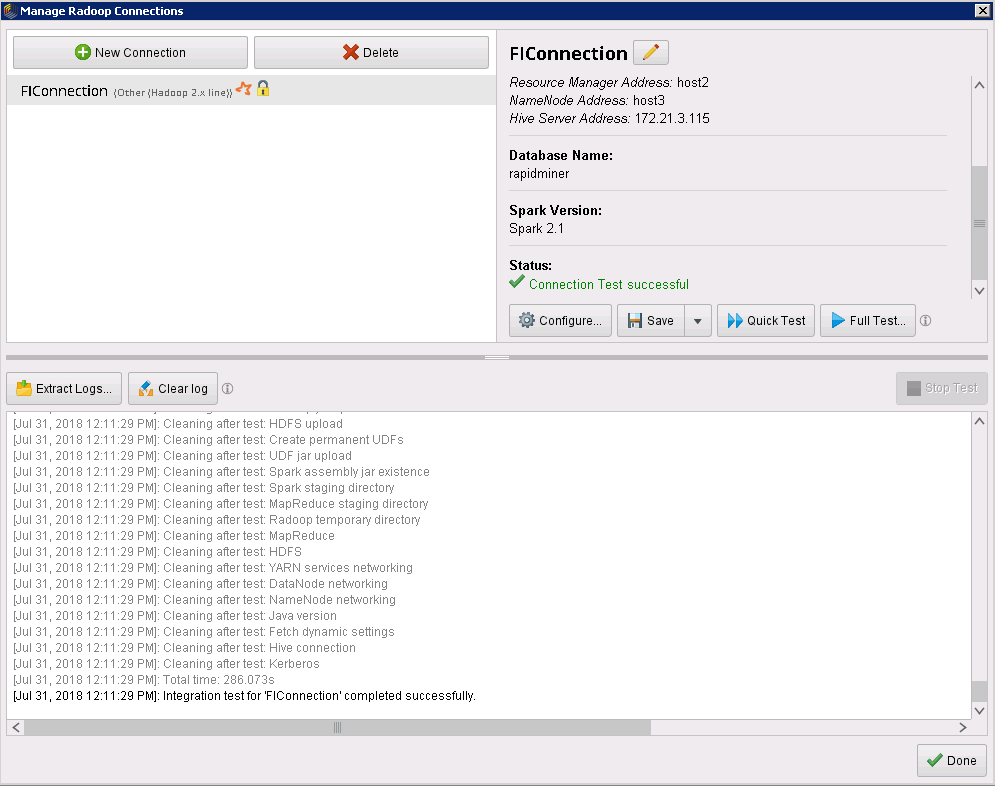
在Manage Radoop Connections 窗口,选中所创建的连接,点击Full test进行完整测试,Test Results显示如下,表明完整测试通过
Radoop样例运行¶
-
在RapidMiner Studio 主页面,Help->Tutorials->User Hadoop->Rapidminer Radoop
- 根据Tutorials的指导运行样例,运行结果如下:

FAQ¶
-
测试连接时,提示ICMP port unreachable/Error retrieving Hive object list问题
- 检查集群中端口绑定程序是否正常运行,绑定的端口是否正确。RapidMiner在测试时,会与集群的88端口连接进行Kerberos认证,而FusionInsight平台对端口进行了规划,Kerberos认证使用的端口是21732。
-
测试Spark时,提示GSS initiate failed
- 检查本地host文件是否添加了集群IP与主机名的对应关系。
-
测试Spark时,将各种版本都测试了一遍,最后提示Spark test failed
- 检查添加的两个Advanced Parameters是否填写正确,其value值中的绝对路径对于每个集群是不一样的,当集群重装后需要修改该值。
-